聊聊链表
数据结构:聊聊链表
幸福穿着节日的盛装欢迎你。 ——威廉•莎士比亚《罗密欧与朱丽叶》
1. 说在前面
大家在学数组的时候小脑瓜里有没有这样的疑惑:为什么数组必须是定长的?为什么数组开太长会编译错误?数组越界为什么不报错?
其实开数组的时候你的电脑的内存里是这样的:
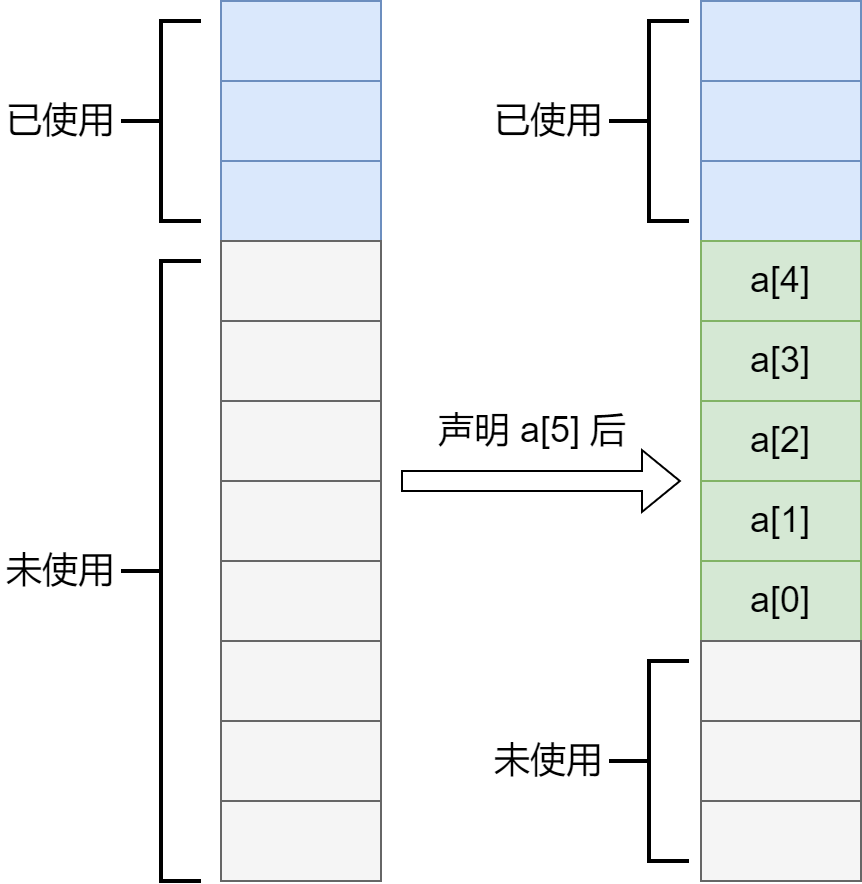
当声明数组大小之后,内存里会往下数相应的空间,然后从下到上依次为数组分配空间,所以你访问 a[5] 实际是访问已使用部分的内存。这又说明,数组占用的是一片连续的空间,而你若是开 a[1000000000] 那么大的数组,计算机很难保证有那么大的连续空间,所以编译器出于一种保护的目的,禁止开那么大的空间。不过有的小伙伴可能发现有时候太大的数组在自己的电脑开不出来,但是在 OJ 上能 AC,这是因为 OJ 的服务器没有这样一种编译时的保护机制,不过当你的程序运行时使用内存过大会强制终止,并返回 MLE。
所以为了克服数组只能定长的弊端,科学家们给出了一些可行的方案,比如变长数组、链表等等。
变长数组顾名思义:长度可变的数组,在定义后可以自动改变长度。满了会自动加长,也就是另外找一片更长的连续空间,然后把自己整个 copy 过去;如果里面的元素太少,自己还会缩短,也就是把自己用不到的部分给释放出去。
这里给出变长数组的代码大家可以留着,大作业或许有用,只能让数组伸长并没有实现缩短:
1 | |
2333是不是有很多你们看不懂的东西?这里我说明一下相关语法:
typedef struct Vector {...} *VecPtr;:typedef是 type define 的缩写,就是类型名字重定义,这里的用法是将这句话和定义结构体写到一起去了,最后的*VecPtr,意思是让Vecptr成为struct Vector的指针类型
题外话:在 C++ 里有现成的变长数组可以使用,名字就叫
vector,vector 是向量的意思,大家线性代数都学过高维向量吧,你懂的。VecPtr是 vector pointer 的缩写,即“数组指针”。
->运算符是 C 语言中结构体的一种操作,表示“给一个结构体指针,找到那个结构体并访问其元素”。例如vec->length就等于&vec.length,但是用->显得更生动形象也更推荐。VecPtr vec = (VecPtr) malloc(sizeof(struct Vector));:malloc()函数是 memory allocate 的缩写,即“内存分配”,括号里的参数是内存的大小,一般写作n * sizeof(...),表示分配那么多空间,返回那片空间的起始地址(空指针void *类型),函数前面的(VecPtr)是强制类型转换,将void *指针转换为VecPtr类型才能给参数赋值。后面的(int *)同理。malloc()函数需要头文件<stdlib.h>!!!realloc顾名思义,是内存重新分配,有两个参数,第一个参数是旧地址,第二个参数是新空间的大小。就是开辟一块新空间,然后把旧地址里的东西整个 copy 过去并释放旧空间,最后返回新空间的起始地址,记得加上类型转换!
可能看到上述写法你们会有点不适应,但是在以后的学习中,尤其是最重要的链表和树,结构体指针是必须要熟练掌握的!
2. 初识链表(Linked List)
变长数组还是有个缺点,当你的内存紧张的时候,找不到一块足够大小的连续空间,那么数组的加长就会失败。为了能榨干计算机的每一处内存,科学家就想出了这个“恶毒”的方案。数据的存储并不连续,每插入一个数据就在内存中寻找一小块内存用掉,直到内存被完全用光为止。
链表画出来大概是这样的:

链表的每一个方块被称为结点(Node),除了最后一个以外,每一个结点都连接着后一个结点,所以只要有链表的头部结点,就可以往后一个一个找以访问到所有结点。但是这种方式有一个缺点:不能像数组一样快速访问第某个节点(这种被称作随机访问),想访问第 k 个结点就必须从头结点开始一个一个数,数到 k 才行,因此链表的随机访问的平均时间复杂度是 \(O(N)\),而数组是 \(O(1)\)。
3. 操作和实现
1. 链表的定义
1 | |
以上是定义链表结构体的代码
int val:链表存放数据的值,就是图里的 data 块,其实是可以根据需要灵活多变的;struct Node * next:这是定义一个next元素,类型是链表的指针,用来保存下一个结点的地址,末尾结点的next是空的(即NULL),在图里用 \(\wedge\) 符号表示。(你问我为啥不用List?List是在后面定义的,在前面就用它也过不去编译啊)- 最后将这个结构体的指针重命名为
List。
2. 链表的构造
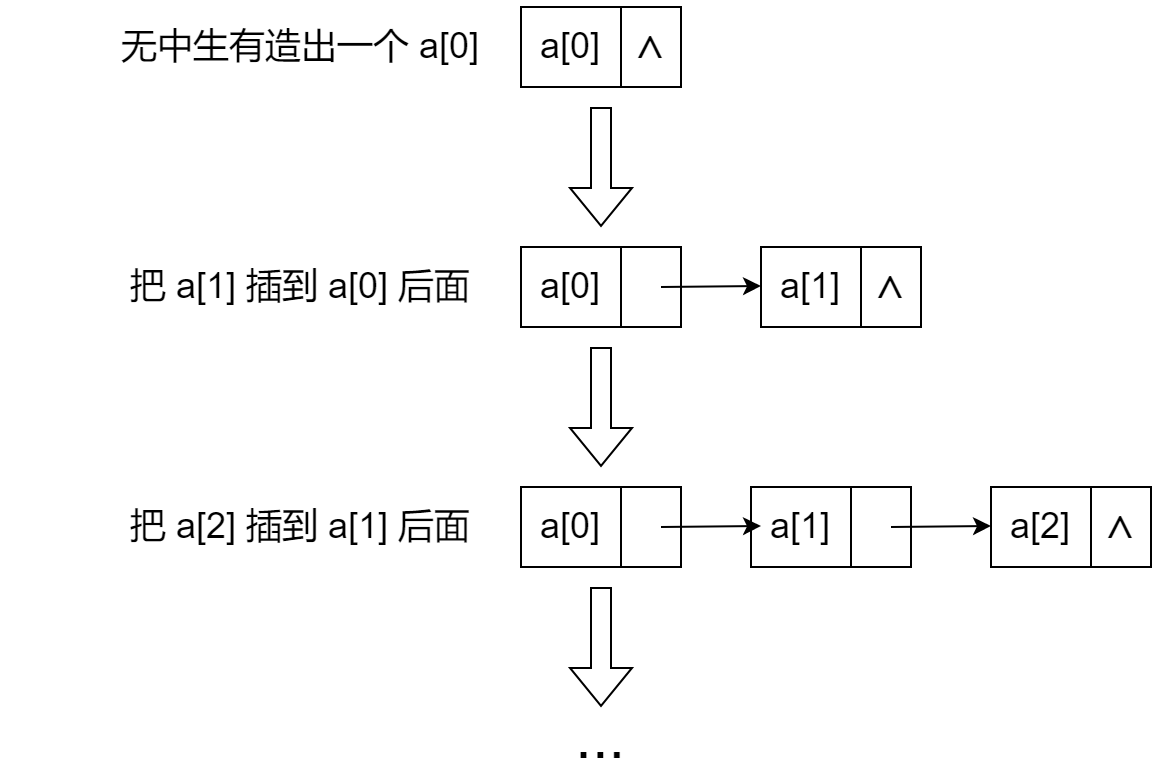
这里举这样一种情况为例:把一个长度为 \(n\) 的数组转化为链表。这里有两个问题需要我们来解决:
- 当链表是空的时候我们需要无中生有造出一个表头来;
- 从第二个元素开始,构造的过程就是一个一个往后插入元素。
大家看图:
代码实现:
1 | |
以上代码墙裂建议充分理解并熟练掌握。
3. 链表的遍历、随机访问和查找
y1s1 这都没啥难的,就是大概看看熟悉熟悉。
1. 遍历:打印链表
1 | |
2. 随机访问:链表第 k 个元素(从 0 开始计数)
1 | |
注意 k 大于等于链表长度时返回 -1。
3. 查找并返回找到结点的指针
1 | |
4. 链表的插入
给定链表的某结点 p,要在 p 的后面插入元素 item,如何操作?看图:
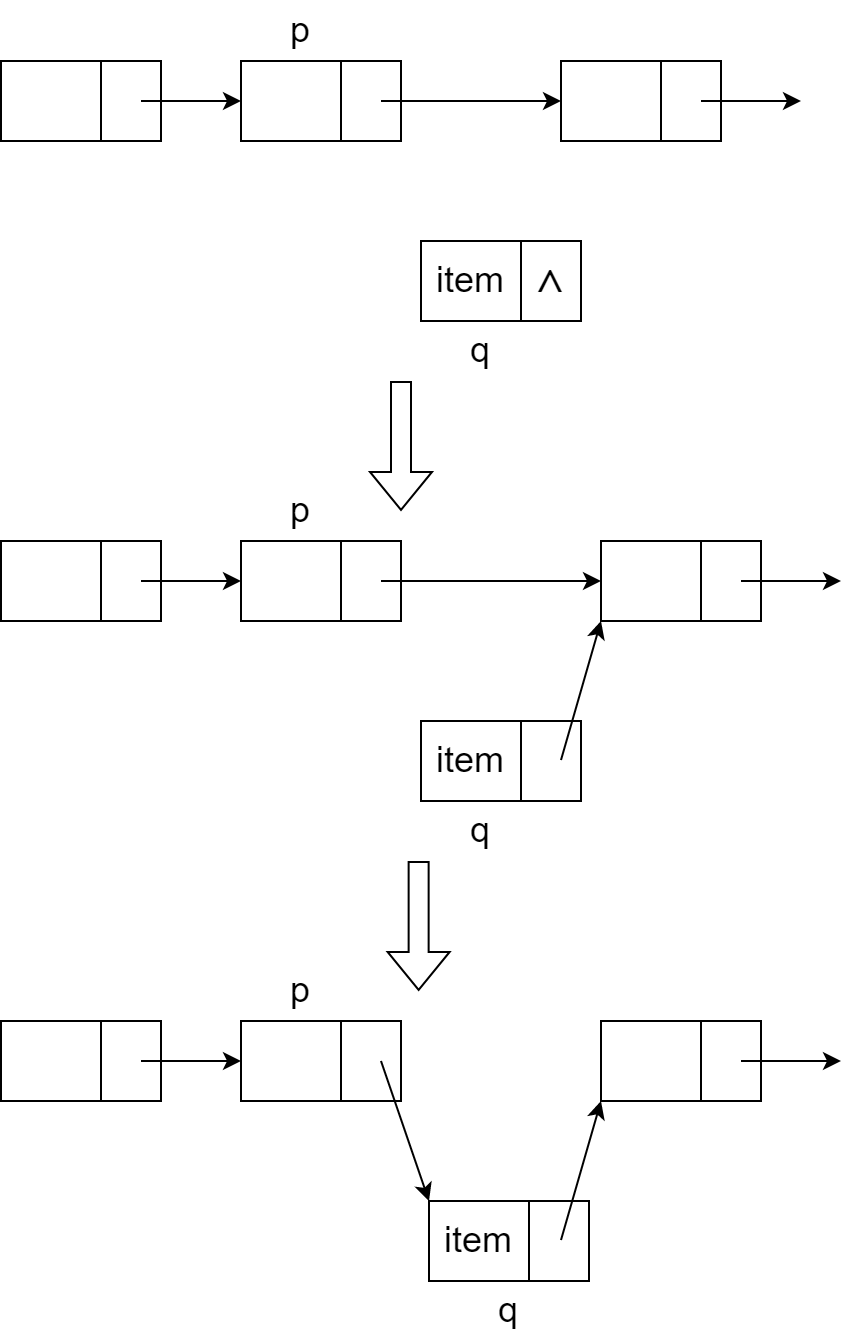
需要注意的是:一定是先让 q 指 p->next 再让 p 指 q。顺序颠倒的话 p 后面的结点就丢了!
重要的就是把图记下来,代码很容易写:
1 | |
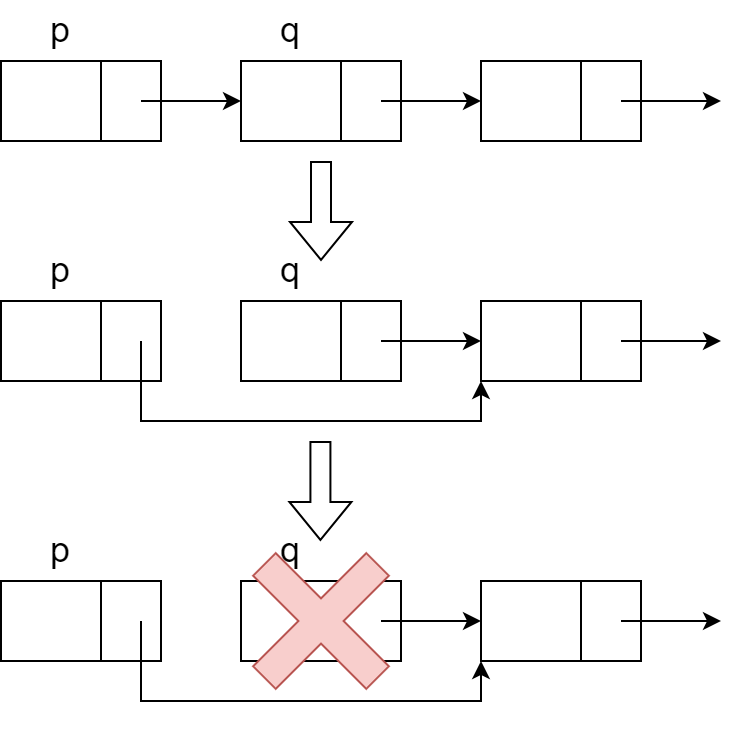
5. 链表的删除
注意链表在删除时不能直接删除要删除的结点,而要给出它的前一个结点才能操作。
1 | |
当 p 是链表尾时无法删除,返回-1,删除成功则返回 0。
free()函数接收一个指针,并将指针所指的空间释放掉留给以后使用。如果我们只写p->next = p->next->next虽然也能删除,但是吧……这是既浪费空间又不很道德的~如果你的程序跑在长期运行的服务器上,就可能会发生“内存泄漏”,明明没有存多少东西,内存就满了,所以我们要养成好习惯,合理利用内存哈。
4. 总结
当给定要插入删除的位置时,链表可以在 \(O(1)\) 的时间复杂度内完成插入删除操作。而数组想插入删除,就不得不咣咣咣移动后面的所有元素腾出地方或者往前缩,时间复杂度为 \(O(N)\)。
但是由于数组是连续空间,支持快速下标访问,所以可以在有序数组上进行二分查找。(数组扳回一局)
以后学到的树和图都是以链表为基础,所以熟练掌握链表的写法是非常重要的!!!
可以看到我写的代码都是已经封装好的函数,我建议大家养成好习惯,把一些细节的代码都封装成函数,并且起一个清楚的名字,在main()函数里反复根据需求调用函数,这样做好处很多:
- 函数具有可移植性,以后用的时候(包括用自己的电脑考试)可以直接 copy;
- 你的程序逻辑非常清晰,助教读了之后非常乐意帮你改 bug;
- 你自己写出来也觉得很有成就感。
建议大家反复研究示例代码,深刻理解指针的用法,记住插入和删除的流程。
由于链表大量使用指针,所以初学者写程序的时候很可能会犯野指针的错误,当你发现你的程序跑着跑着就死了。DEV C++ 或 CLion 的断点调试功能能很快帮你找到问题所在哦。
另外单纯的链表在做题中较少使用,但是将链表的尾部连到头部,就成了循环链表,如果给链表定义left和right两个指针就成了双向链表,它们有更丰富的功能等着你们去探索呢~
那么……祝大家享受编程的乐趣,成绩更上一层楼!