BUAACT-Chap01-概论
第一章 概论
1.1 基本概念
计算机五部分:输入、输出、运算器、控制器、存储器。——邵兵
低级语言:
字位码、机器语言、汇编语言。
特点:与特定的机器有关,功效高,使用复杂、繁琐、费时、易出错;
高级语言:
Fortran、Pascal、C语言等。
特点:不依赖具体机器,移植性好,对用户要求低,易使用,易维护。
源程序:
用汇编或高级语言编写的程序。
目标程序:
用目标语言表示的程序。
翻译程序:
将源程序转换为目标语言的程序。它是指各种语言的翻译器,包括汇编程序和编译程序。
源程序是目标程序的输入,目标程序是翻译程序的输出。
汇编程序:
源程序用汇编语言书写,经翻译得到机器语言的程序。
编译程序:
源程序用高级语言书写,经加工得到低级语言程序。编译时和运行时是明显分开的。运行效率高。
解释程序(Interpreter):
对源程序进行解释执行的程序。编译时和运行时是结合在一起的。运行效率低。但现实中解释程序用得多。例如 JavaScript、Python。
1.2 编译过程
所谓编译过程是指将高级语言程序等价翻译为目标程序的过程。
习惯上是将编译划分为五个基本阶段:
- 词法分析;
- 语法分析;
- 语义分析、生成中间代码;
- 代码优化;
- 生成目标程序。
1.2.1 词法分析
任务:分析和识别单词。
源程序是由字符序列构成的,词法分析扫描源程序(字符串),根据语言的词法规则分析并识别单词,并以某种编码形式输出。
单词(token):
是语言的基本语法单位,一般分为四大类:
- 语言定义的关键字或保留字(如 BEGIN、END、IF);
- 标识符;
- 常数;
- 分界符(运算符)。
1.2.2 语法分析
任务:根据语法规则(即语言的文法),分析并识别出各种语法成分,如表达式、各种说明、各种语句、过程、函数、程序等,并进行语法正确性检查。
1.2.3 语义分析、生成中间代码
任务:对识别出的各种与法成分进行语义分析,并产生相应的中间代码。
- 中间代码:一种介于源语言和目标语言之间的中间语言形式。(四元式)
- 生成中间代码的目的:
- 便于优化处理;
- 便于编译程序的移植(中间代码不依赖于目标计算机)
四元式(三地址指令)
对于例子:X1 := (2.0 + 0.8) * C1
| 运算符 | 左运算对象 | 右运算对象 | 结果 |
|---|---|---|---|
| + | 2.0 | 0.8 | T1 |
| * | T1 | C1 | T2 |
| := | X1 | T2 |
1.2.4 代码优化
任务:得到更高质量的目标程序。(从效率上和空间上)
1.2.5 生成目标程序
由中间代码很容易生成目标程序(地址指令序列)。这部分工作与机器关系密切,所以要根据具体机器进行。在做这部分工作时(要注意充分利用累加器),也可以进行优化处理。
注意:在翻译成目标程序的过程中要注意语义等价。
1.3 编译程序的构造
1.3.1 编译程序的逻辑结构
按逻辑功能不同,可以将编译过程划分为五个基本阶段。与此对应,我们将实现整个编译过程的编译程序划分为五个逻辑阶段。
在上述五个阶段中都要做两件事:
- 建表和查表
- 出错处理
表格管理(符号表组织):在整个编译过程中始终都要贯穿着建表(填表)和查表的工作。即要及时地把源程序中的信息和编译过程中所产生的信息登记在表格中,而在随后的编译过程中同时又要不断地查找这些表格中的信息。
出错处理:规模较大的源程序难免有多种错误。编译程序必须要有出错处理的功能,即能诊察出错误,并向用户报告错误性质和位置,以便用户修改源程序。出错处理能力的优劣是衡量编译程序质量好坏的一个重要指标。
典型的编译程序有 7 个逻辑部分:
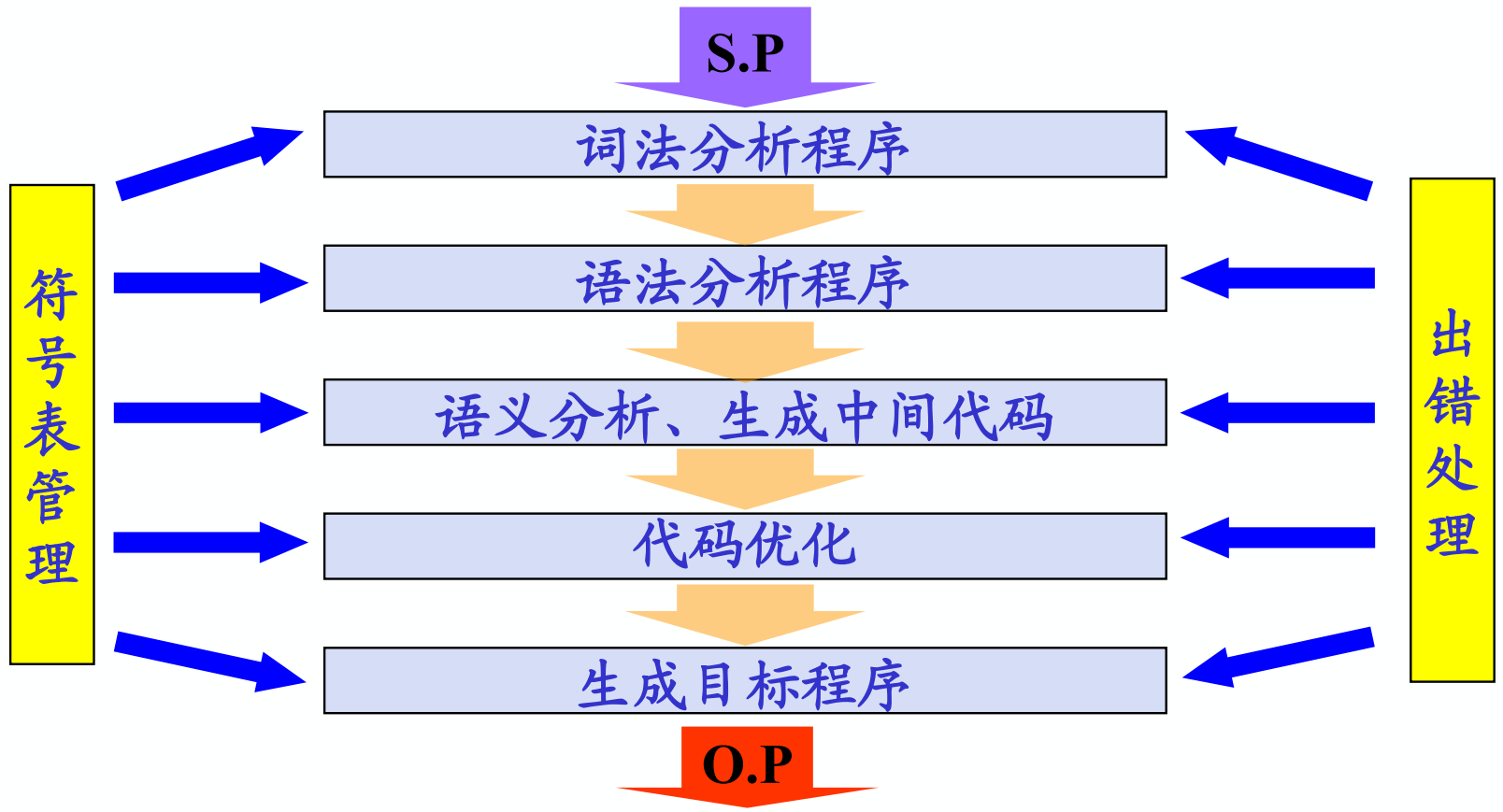
1.3.2 遍(PASS)
遍:对源程序(包括源程序的中间形式)从头到尾扫描一次,并做有关的加工处理,生成新的源程序的中间形式或目标程序,通常称之为一遍。
上一遍的结果是下一遍的输入,最后一遍生成目标程序。
五个基本阶段:是将源程序翻译为目标程序在逻辑上要完成的工作。上一遍的结果是下一遍的输入,最后一遍生成目标程序。
遍:是指完成上述 5 个基本阶段的工作,要经过几次扫描处理。
一遍扫描即可完成整个编译工作的称为一遍扫描编译程序。
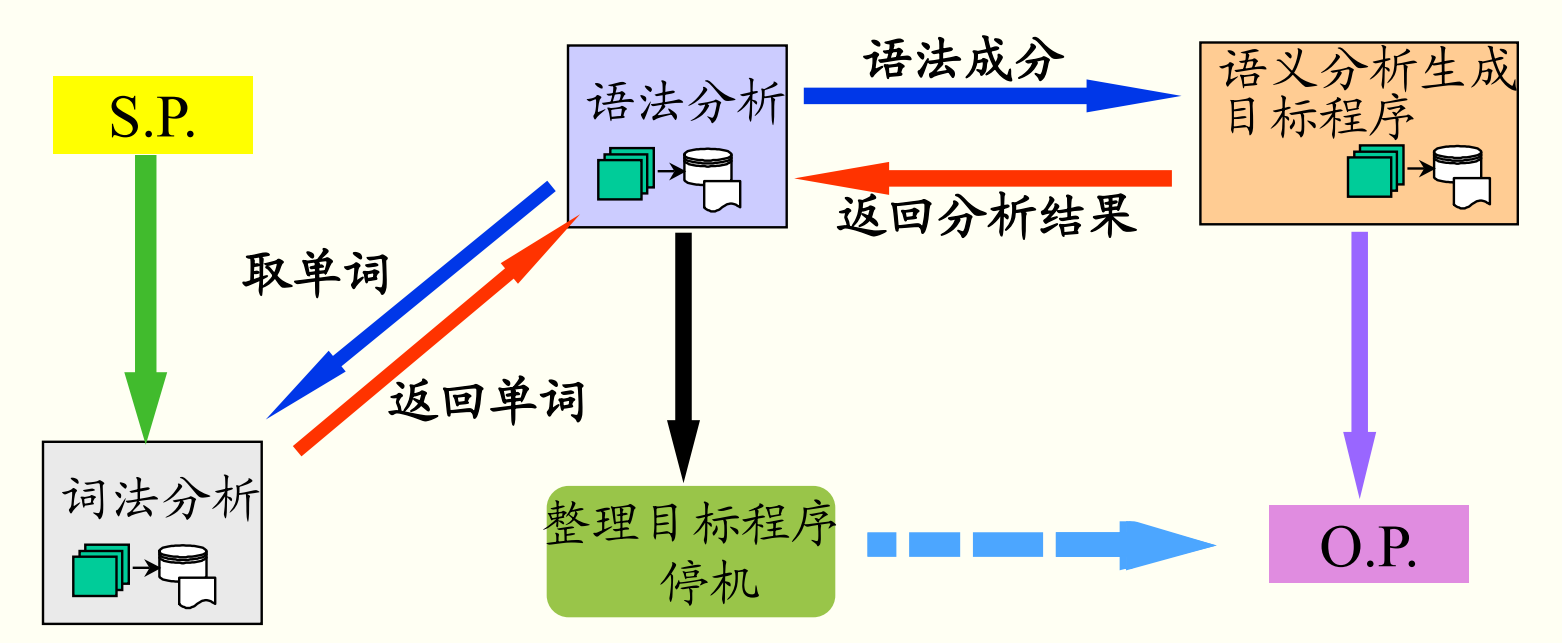
1.3.3 前端和后端
前端:
和目标机器无关的处理。词法分析、语法分析、语义分析、中间代码生成、代码优化。
后端:
和目标机器有关的处理。目标程序的生成(与目标及有关的优化)。
传统编译器分为前端和后端,现代的新型编译器(尤其是 LLVM)还包含一个中端。
1.4 编译程序的前后处理器
源程序:多文件、宏定义和宏调用,包含文件
目标程序:一般为汇编程序或可重定位的机器代码。
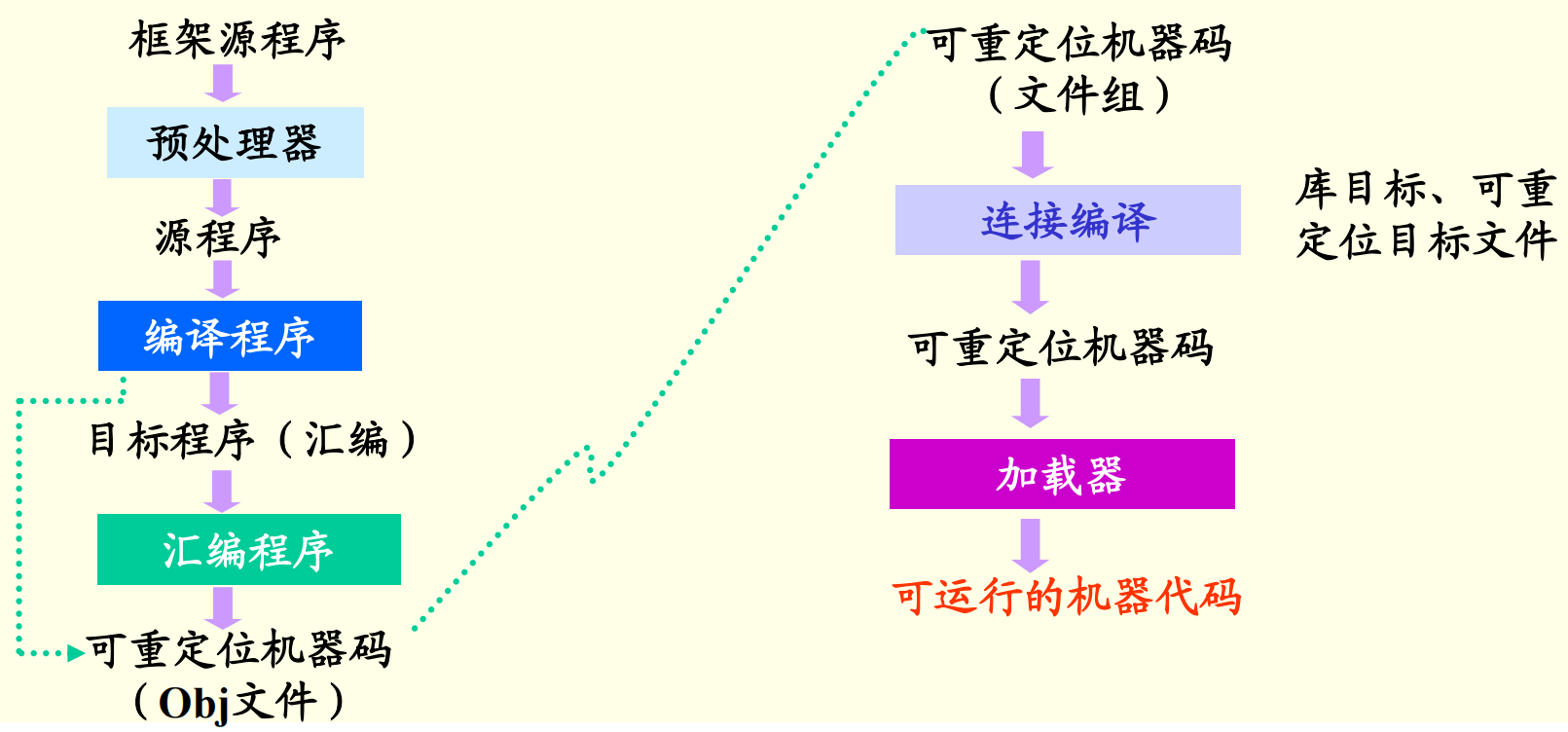
1.5 编译技术的应用
- 语法制导的结构化编译器;
- 程序格式化工具;
- 软件测试工具;
- 程序理解工具;
- 高级语言的翻译工具等等。