BUAACO-MIPS程序设计——递归函数
MIPS 程序设计——递归函数
我们在手动编写 MIPS 程序时需要关注以下寄存器:
1 | |
编写函数代码的整个流程:
- 计算出需要函数所需运行栈的大小;
- 传入参数(存入
$a0-$a3寄存器或运行栈中); jal跳转进函数代码;- 函数压栈,
$sp下沉; - 获取参数(如果有参数被保存在运行栈上);
- 计算运行工作,同时时刻注意调用其它函数前将寄存器保存到栈上;
- 将返回值存进
$v0(如果有的话); - 函数出栈,
$sp上升; - 取回
$ra(如果需要的话); jr跳转回调用处。
下以计算斐波那契数的程序为例介绍一下详细过程。
1 | |
函数定义代码:
1 | |
为了保护两个 fib 函数的返回值,首先改写为:
1 | |
要计算这个函数的运行栈的大小,首先要明白函数的运行栈是什么,以及为什么要有运行栈。汇编语言在进入一个函数以后,其寄存器就从调用者(Caller)转交给了被调用者(Callee)。当函数返回的时候,寄存器已经被 Callee 使用过了,此时的寄存器信息对于 Caller 来说是不可信的,因此 Caller 在调用函数之前,需要将自己有用的信息保存在内存里,这段内存被称作 Caller 的运行栈。运行栈通常需要保存:
- 函数的参数;
- 函数里定义的变量;
- 返回地址
$ra。
其中 $ra
是必须要保存的,参数和变量视情况而定,有的时候可以适当优化,具体情况以下会详细介绍。
对于 fib 函数,我们如果不做优化的话,可以假设
n,a,b,$ra
都需要保存,因此 fib 的运行栈是 4 个字(word)也就是 16
个字节(byte),示意图如下:
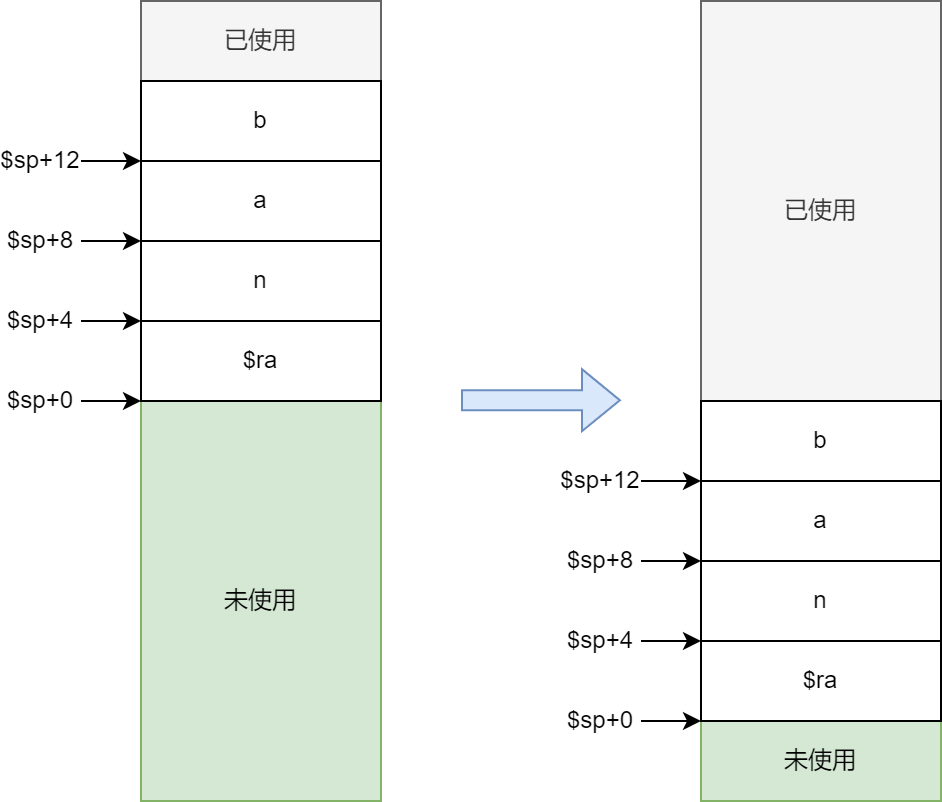
左图白色部分是一个 fib 函数的运行栈,当这个函数作为
Caller 调用下一个 fib 函数以后,Callee
的运行栈就如右图的白色部分所示。
下面正式开始编写 fib 的代码,首先写下:
1 | |
要知道 $a0 里面含有的是传入 fib
的参数(稍后会看到 $a0 是怎么来的),因此这两句话在:
- 栈指针下降 16 个字节;
- 将
$ra保存在内存里$sp + 0的位置;
然后接着编写判断语句部分:
1 | |
将 if 语句稍微变一下形式,当 $a0 大于 1
时执行 lab: 后面的语句,否则继续向下执行。注意 MIPS 约定用
$v0 作为一个函数的返回值寄存器,当 Caller 执行完 Callee
需要拿返回值的时候会到 $v0
里面找,因此在函数返回之前需要把返回值放到 $v0
里面。接下来的 3~5
行就是函数返回的一套标准操作,把开头的逆过来就好了。
下面是 lab: 后面的代码:
1 | |
注意从
int a = fib(n - 1);开始要调用函数了,因此我们要保护寄存器,由于
$ra 已经被保存过了,在这里只保存一下 $a0
就好,2~5 行的作用分别是:
- 将参数
n保存在$sp + 4的位置; - 传入参数
n - 1 - 调用
fib函数; - 将
fib(n - 1)的返回值赋给变量a并保存在$sp + 8的位置。
下面看第 7 行,注意此时的 $a0 已经不再是我们之前的
$a0 了,也不一定是 $a0 - 1,它已经被 Callee
“污染”了,所以我们想拿到参数 n 只能从栈的
$sp + 4 的位置拿。之后就是调用 fib(n - 2)
了。
11~12 行是,首先从 $sp + 8 的位置取出变量 a
放到 $t0 里面,再令 $v0 等于
a + fib(n - 2)(可以看到变量 b
似乎并没有起作用)。
最后三句还是标准流程退出函数。
因此我们在确定函数的运行栈的大小的时候,可以只考虑 Caller 函数在调用其它函数之前需要保护的变量有几个,如果一个函数不用保护变量的话,也是可以不需要运行栈的。
在本题中实际上变量 b
不需要单独的空间来保存,而是可以通过寄存器计算来优化掉,因此
fib 函数的实际运行栈大小只有 12 字节。
注意如果一个函数体调用了其它函数(执行了 jal),那么就要考虑保护寄存器,其中 $ra 是必须要保护的!
补充了 main 函数的完整代码如下:
1 | |