Python 爬虫框架——Scrapy
入门实战
1 框架简介
爬虫技术是一种自动化获取互联网上信息的技术,通过编写程序模拟人类浏览器的行为,爬虫可以访问并获取网页上的各种数据。它可以自动点击链接、填写表单、提取文本等,常用于搜索引擎的数据抓取、网站的数据分析与挖掘等领域。
举个例子,某一天你猫瘾犯了,一定要看大量的猫猫图片才能缓解,于是你准备从百度图片下载大量的猫猫照片。你一个个右键单击图片、保存图片、点击下一页……而这一过程如果用脚本来自动化实现,就是爬虫啦。
目前爬虫的手段大概有两大类:基于网络请求 requests
和模拟浏览器的 selenium,我们本次讲解的爬虫框架
Scrapy 就是利用请求来获得网页信息。
Scrapy 的官网如下:scrapy.org ,框架的优点有:
高效性:Scrapy
采用异步处理和多线程机制,可以同时处理多个请求,提高爬取效率;
可扩展性:Scrapy
提供了丰富的中间件、插件和扩展点,可以根据需要进行自定义扩展和功能增强
灵活性:Scrapy
采用了基于规则的爬取方式,可以通过配置文件定义爬取规则,灵活适应不同的网站结构
支持分布式:Scrapy
支持分布式爬取,可以通过分布式架构提高爬取效率和稳定性
……
2 任务目标
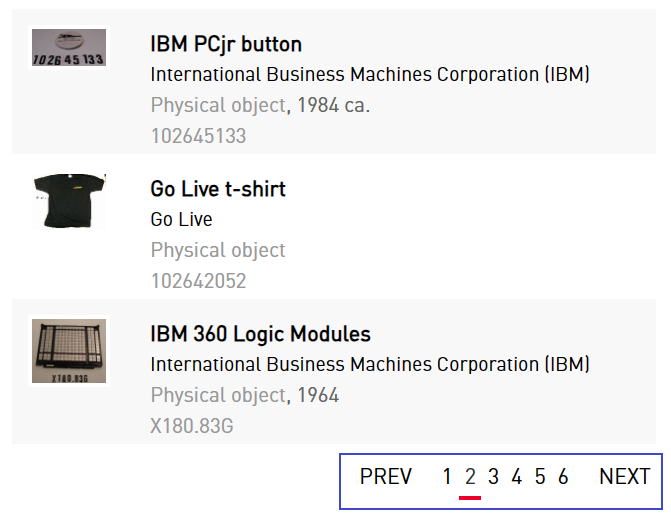
本次我们要爬取的内容为美国计算机历史网站藏品数据 ,首先进入Catalog
Search | Computer History Museum ,在搜索框输入 "s",接着点击
"Physical Object",看到了四万多条结果,我们再随便点击进去一个藏品,例如
"GT-2000 Graphic Tablet",看到里面有 Title、Catalog Number、Type
这三个必要的属性和 Description、Manufacturer、Dimensions
等可选属性。我们的目的就是将这四万多结果的信息以 json
文件的形式保存起来,例如:
1 2 3 4 5 6 7 8 9 10 { "title" : "GT-2000 Graphic Tablet" , "catalog_number" : "102647165" , "type" : "Physical object" , "description" : "This items is still sealed in its original box..." , "manufacturer" : "Radio Shack, A Division of Tandy Corporation" , "dimensions" : "in box: 3.5 x 14.75 x 15 1/2 in" } { ...}
3 爬取思路
首先当你在网站中点击翻到第二页以后,如下图:
你会发现网站的 url 发生了变化:
1 https://www.computerhistory.org/collections/search/?s=s&f=physicalobject&page=2
后面多了 &page=2,也就是说这个
&page=xx
就是控制页面跳转的。翻页之后我们只需要“点击”展品中每一个展品的标题就能进入展品详情页面,再获取展品的详细信息就行了。
4 爬虫实现
4.1 配置和新建项目
4.1.1 安装 Scrapy
使用命令:
4.1.2 初始化项目
使用命令:
1 $ scrapy startproject demo_project
然后进入项目并新建爬虫:
1 2 $ cd demo_project
第一个 computerhistory 表示项目的名称; 后面的 www.computerhistory.org 表示爬虫要访问的域名。
看到信息:
1 2 Created spider 'computerhistory' using template 'basic' in module:
表示爬虫创建成功。打开项目,里面的目录结构如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 D:.
4.2 定义数据类
第一步就是确定我们数据的存储格式,也就是 json 中的字段。我们需要在
items.py 中定义一个类 ComputerHistoryItem
来保存我们爬取的结果:
1 2 3 4 5 6 7 8 9 10 import scrapyclass ComputerHistoryItem (scrapy.Item):type = scrapy.Field()
4.3 爬虫初尝试
打开 spiders/computerhistory.py
我们会看到已经生成了一些代码:
1 2 3 4 5 6 7 8 9 10 import scrapyclass ComputerhistorySpider (scrapy.Spider):"computerhistory" "www.computerhistory.org" ] "https://www.computerhistory.org" ] def parse (self, response ): pass
首先我们要修改一下 start_urls,暂时让它变成:
1 start_urls = ["https://www.computerhistory.org/collections/search/?s=s&f=physicalobject&page=1" ]
然后我出门需要在开头引用刚刚定义的
ComputerHistoryItem:
1 from demo_project.items import ComputerHistoryItem
之后我们要修改 parse 函数。
parse 是对 start_urls 的每一个 url 执行的,你可以认为在执行 parse 的时候已经打开了一个url,其中的响应内容就保存在 response 参数里。
我们先定一个小目标,暂时只获取 title 和
type(因为这两个不需要点进详情可以直接从列表取得)。如何定位元素的位置呢?我们就需要
XPath 来帮忙了。
XPath 是一种用于在 XML 文档中定位和选择节点的查询语言。它可以通过路径表达式来指定节点的位置,并且可以根据节点的属性、关系和内容进行筛选和匹配。XPath 具有简洁的语法和强大的功能,可以用于处理和分析 XML 数据。
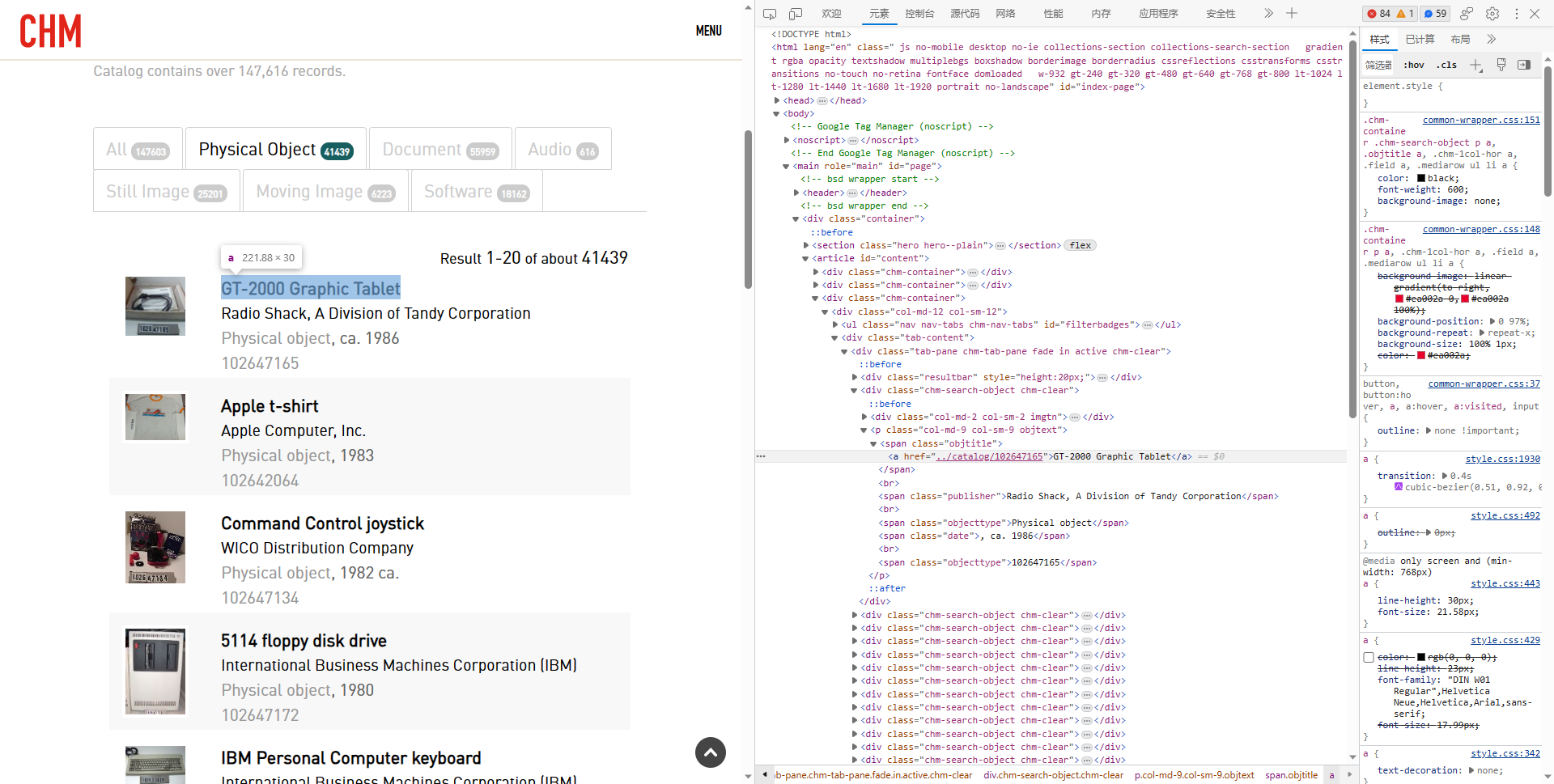
我们需要在这个页面中找到所有的
title、catalog_number 和
type,在浏览器按下 F12,通过 Ctrl+Shift+C
从页面中找到标题元素看到:
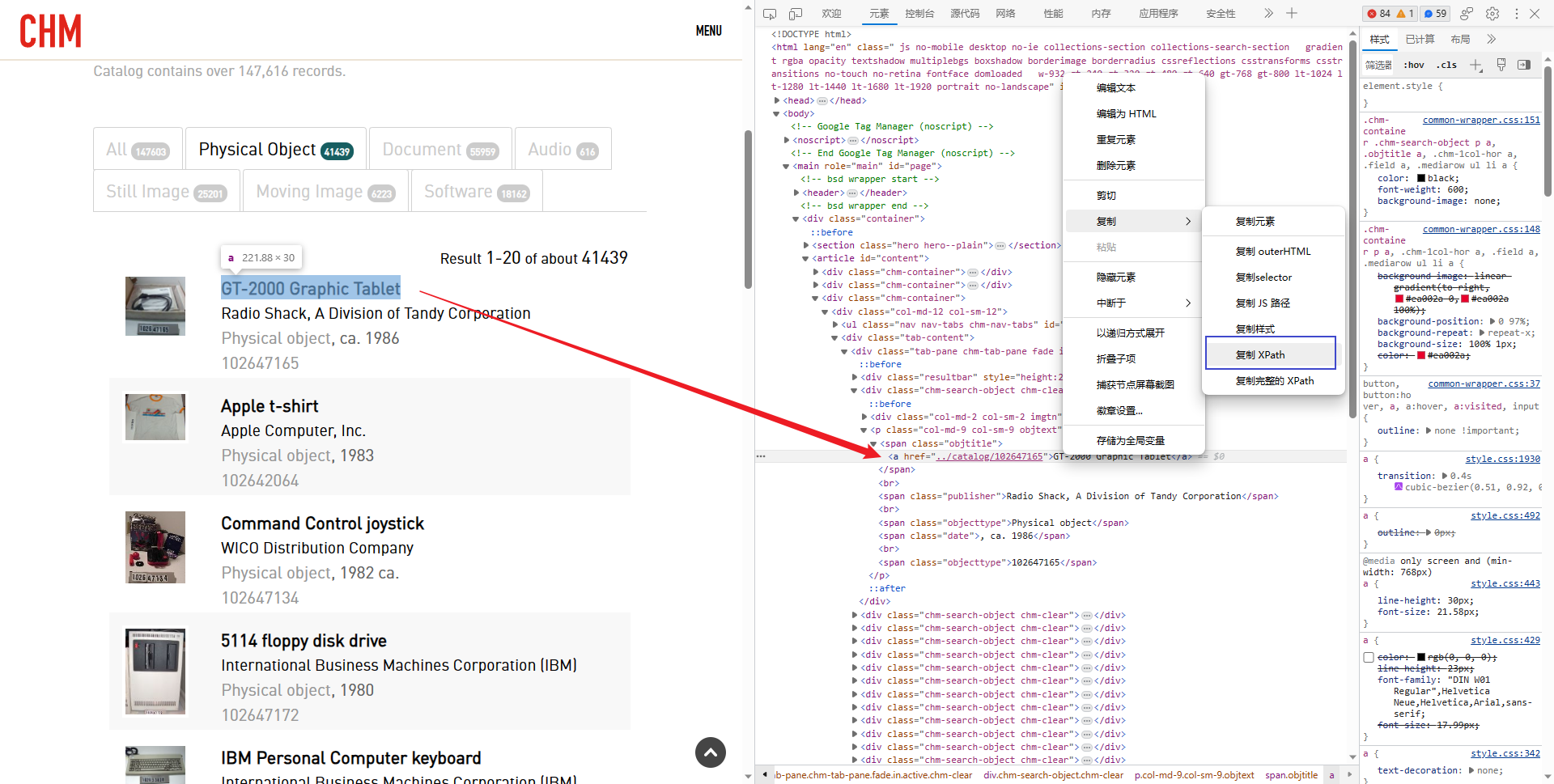
右键点击 html 代码区那个框,复制 XPath:
再按 Ctrl+F,粘贴进去:
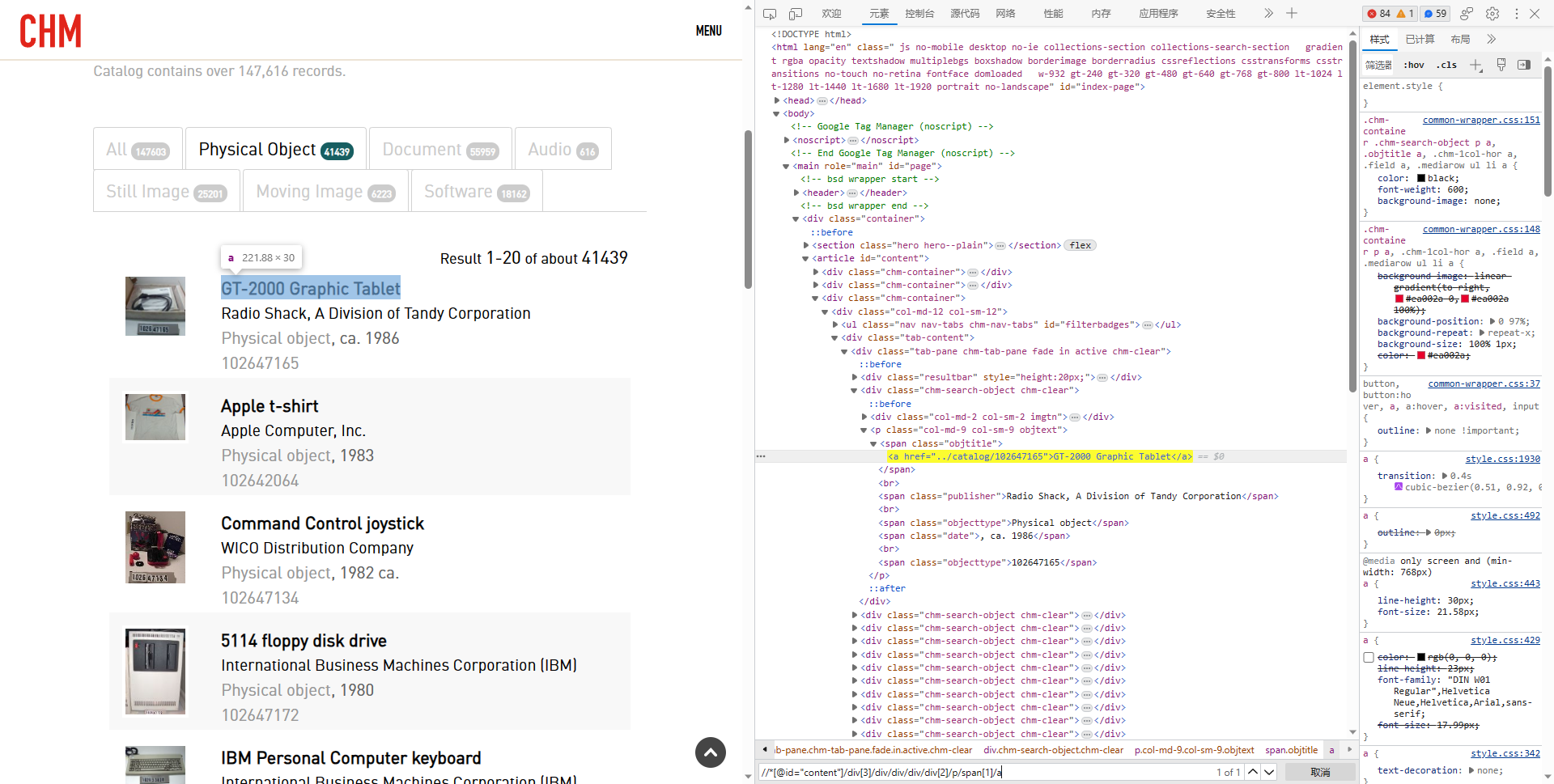
把
//*[@id="content"]/div[3]/div/div/div/div[2]/p/span[1]/a 的
[2] 删掉,看到我们一共找到了 20 个结果,没错,这样就找到了
title 列表了。同样的方法,再寻找 type 的 XPath
路径。
如果你查找 //*[@id="content"]/div[3]/div/div/div/div/p/span[5] 可能会发现结果不一定是 20 个,那是因为有的 Catalog Number 不在那个位置,应该改为 span[last()]
将 parse 的代码修改为:
1 2 3 4 5 6 7 8 def parse (self, response ):'//*[@id="content"]/div[3]/div/div/div/div/p/span[1]/a/text()' ).extract()'//*[@id="content"]/div[3]/div/div/div/div/p/span[last()]/text()' ).extract()for title, catalog_number in zip (title_list, catalog_number_list):"title" ] = title.strip()"catalog_number" ] = catalog_number.strip()yield item
在 response.xpath() 方法中,末尾加上 /text() 才能获取文字内容,最后的 .extract() 表示抽取出来保存在列表里; .strip() 表示删除头尾的空白字符yield item 表示每次调用返回一个 item
最后 computerhistory.py 的内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import scrapyfrom demo_project.items import ComputerHistoryItemclass ComputerhistorySpider (scrapy.Spider):"computerhistory" "www.computerhistory.org" ]"https://www.computerhistory.org/collections/search/?s=s&f=physicalobject&page=1" ]def parse (self, response ):'//*[@id="content"]/div[3]/div/div/div/div/p/span[1]/a/text()' ).extract()'//*[@id="content"]/div[3]/div/div/div/div/p/span[last()]/text()' ).extract()for title, catalog_number in zip (title_list, catalog_number_list):"title" ] = title.strip()"catalog_number" ] = catalog_number.strip()yield item
在项目根目录下输入以下命令运行:
1 $ scrapy crawl computerhistory -o output.jsonl
如果在你的目录下看到了 output.jsonl
而且里面有内容的话,恭喜初步尝试已经成功了。
4.4 爬虫伪装
下面我们准备大量爬取数据,不过既然是大量,就面临着就反复请求被发现的风险,因此确保安全我们要先伪装一下。
4.4.1 伪造 User-Agent
User Agent中文名为用户代理,简称
UA。它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU
类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等等。也就是说,假设:一个平台,设置了
UA
权限,必须以浏览器进行访问。当你使用爬虫脚本去访问该网站的时候,就会出现,访问失败、没有权限、或者没有任何资源返回的结果等错误信息。
但好在刚才的尝试成功说明这个网站没有鉴别
UA,虽然如此,为了保险还是加一下比较好。
Scrapy 提供了一个很方便的添加请求头的方法——中间件
middleware,就是可以把你即将要发送的请求拦截下来,装上一个 UA
再发出去。我们首先下载 fake-useragent
工具包(显然就是一个专门伪造 UA 的工具):
1 $ pip install fake-useragent
然后打开 demo_project/settings.py,找到:
解除注释变成了: 1 2 3 4 5 "demo_project.middlewares.DemoProjectDownloaderMiddleware" : 543 ,
接着打开
demo_project/middlewares.py,先import fake_useragent
,再找到 DemoProjectDownloaderMiddleware 类下面的
process_response 方法,加上:
1 2 3 4 5 def process_request (self, request, spider ):'User-Agent' ] = ua.randomprint ("User-Agent: " , request.headers['User-Agent' ])return None
再运行一下爬虫,如果发现有类似以下输出,说明添加 UA 成功:
1 User-Agent: b'Mozilla/4.0 (Windows; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727)'
4.4.2 随机暂停
来自同一 ip
的高频率的访问可能会被网站发现,进而受到惩罚,因此我们应该采取温和 一点的策略,设置一个随机暂停,让我们的爬虫表现地更像人类,我们仍会使用中间件来处理。首先打开
demo_project/settings.py,在刚刚的
DOWNLOADER_MIDDLEWARES 加上:
1 2 3 4 5 6 7 8 2 "demo_project.middlewares.DemoProjectDownloaderMiddleware" : 543 ,"demo_project.middlewares.RandomDelayMiddleware" : 150 ,
然后打开 demo_project/middlewares.py,开头加上:
1 2 import timeimport random
末尾加上这段代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class RandomDelayMiddleware :def __init__ (self, delay ):self .delay = delay @classmethod def from_crawler (cls, crawler ):"RANDOM_DELAY" , 10 )if not isinstance (delay, int ):raise ValueError("RANDOM_DELAY need a int" )return cls(delay)def process_request (self, request, spider ):0 , self .delay)print ("Delay: %.2fs" % delay)
再运行爬虫,如果发现了类似以下内容:
恭喜你又成功了。
4.4.3 代理 ip
随机暂停的方法还是有缺点的,比如暂停导致的速度慢,而且如果网站的限制规则比较严,也有可能抓住是你在爬虫,因此更好的方法是代理
ip 。代理 ip
的原理是把你的请求发送给不同地区的服务器,让他们作为跳板来访问这个网站,好处是:
分散请求:更加不容易被发现你在爬虫;
无需暂停:爬虫速度更快;
对于海外网站使用代理响应速度更快(如果这个项目爬不下来估计是海外相应太慢了,建议还是搞一个代理
ip)
首先把随机暂停关掉(已经没必要了):
1 2 3 4 5 6 7 8 2 "demo_project.middlewares.DemoProjectDownloaderMiddleware" : 543 ,
然后上网搜搜代理 ip 提供商获取代理 ip
提供服务(抱歉这部分我就不细说了),再在
DemoProjectDownloaderMiddleware 类下面的
process_response 方法中加上:
1 2 3 4 5 6 7 8 9 10 11 def process_request (self, request, spider ):"User-Agent" ] = ua.random"http" : "..." ,"https" : "..." 'proxy' ] = proxies['http' ]return None
4.5 页面跳转
完成了小目标以后,我们开始着手我们最初的正式目标。
之前我们的爬虫里 start_urls 只有一个网址,也只能爬一页
20 条数据,因此我们需要计算要爬取的所有页面,打开
computerhistory.py,删掉 start_urls 并加上
start_requests 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import scrapyfrom demo_project.items import ComputerHistoryItemclass ComputerhistorySpider (scrapy.Spider):"computerhistory" "www.computerhistory.org" ]def start_requests (self ):1 41439 20 + 1 1 ) // 20 + 1 "https://www.computerhistory.org/collections/search/?s=s&f=physicalobject" for i in range (begin_page, end_page + 1 ):"&page=" + str (i)yield scrapy.Request(url=url, callback=self .parse)
start_requests 是 scrapy.Spider:该方法的默认实现是遍历 start_urls,我们可以重写这个方法来修改起始 url;yield scrapy.Request(url=url, callback=self.parse) 是将 url 的请求响应交由 self.parse 处理。
但是我们现在不仅要获得列表,还要想办法点进藏品的详情页,所以逻辑改为:获取列表中所有藏品的详情页的
url,再次请求这个 url ,我们可以另外再写一个方法来处理详情页的
url,parse 就老老实实负责获取链接就行了。
我们可以看到,藏品标题其实是一个 <a>
元素,形如:<a href=".catalog/102647165">GT-2000 Graphic Tablet</a>,在浏览器点击进去其实会跳转到:https://www.computerhistory.org/collections/catalog/102647165,我们可以理解为实际访问的
url 其实是 https://www.computerhistory.org/collections 和
/catalog/102647165 拼接而成的,因此代码这样写:
1 2 3 4 5 6 def parse (self, response ):"https://www.computerhistory.org/collections" '//*[@id="content"]/div[3]/div/div/div/div/p/span[1]/a/@href' ).extract()for url in url_list:2 :]yield scrapy.Request(url, callback=self .parse_item)
@href 可以获取 herf;url[2:] 的作用是去掉 ..;self.parse_item 使我们后面需要补上的。
我们现在我们把详情页的 url 扔给了 parse_item
,让我们来补全这个方法吧:
1 2 3 4 5 6 7 8 9 10 11 12 def parse_item (self, response ):'title' ] = response.xpath('//*[@id="biginfo"]/div[1]/span/text()' ).extract_first().strip()'catalog_number' ] = response.xpath('//*[@id="biginfo"]/div[2]/span/text()' ).extract_first().strip()'type' ] = response.xpath('//*[@id="biginfo"]/div[3]/span/text()' ).extract_first().strip()'//*[@id="content"]/div[3]/*' )for selector in info_selectors:'h4/text()' ).extract_first().strip()if header in item_name:'text()' ).extract()[1 ].strip()yield item
info_selectors 是一个 div 框,我们需要从里面找出需要的可选信息;XPath 语法中开头不加 // 代表从当前选择器开始找; item_name:只是一个名字的映射字典,后面会补上。
而且我们需要在 items.py 中加上一个转换的字典:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import scrapy'Description' : 'description' ,'Manufacturer' : 'manufacturer' ,'Dimensions' : 'dimensions' ,class ComputerHistoryItem (scrapy.Item):type = scrapy.Field()
并在 computerhistory.py 的开头添加:
1 from demo_project.items import item_name
最后的整个 computerhistory.py 应该是:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import scrapyfrom demo_project.items import ComputerHistoryItem, item_nameclass ComputerhistorySpider (scrapy.Spider):"computerhistory" "www.computerhistory.org" ]def start_requests (self ):1 41439 20 + 1 1 ) // 20 + 1 "https://www.computerhistory.org/collections/search/?s=s&f=physicalobject" for i in range (begin_page, end_page + 1 ):"&page=" + str (i)yield scrapy.Request(url=url, callback=self .parse)def parse (self, response ):"https://www.computerhistory.org/collections" '//*[@id="content"]/div[3]/div/div/div/div/p/span[1]/a/@href' ).extract()for url in url_list:2 :]yield scrapy.Request(url, callback=self .parse_item)def parse_item (self, response ):'title' ] = response.xpath('//*[@id="biginfo"]/div[1]/span/text()' ).extract_first().strip()'catalog_number' ] = response.xpath('//*[@id="biginfo"]/div[2]/span/text()' ).extract_first().strip()'type' ] = response.xpath('//*[@id="biginfo"]/div[3]/span/text()' ).extract_first().strip()'//*[@id="content"]/div[3]/*' )for selector in info_selectors:'h4/text()' ).extract_first().strip()if header in item_name:'text()' ).extract()[1 ].strip()yield item
4.6 更优雅地导出为
json 以及结果去重——pipeline
假设这样一个情景,你的爬虫爬一半突然停了,你又想重新运行接着爬,就需要有这样一个去重机制,我们可以使用
pipeline 来实现这个。
第一步是在 setting.py 找到以下内容并解除注释:
1 2 3 4 5 "demo_project.pipelines.DemoProjectPipeline" : 300 ,
然后打开 pipelines.py,改为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import jsonfrom itemadapter import ItemAdapterfrom scrapy.exporters import JsonLinesItemExporterclass DemoProjectPipeline :set ()def __init__ (self ):"""初始化函数""" with open ("output.jsonl" , "r" , encoding="utf8" ) as f:for line in lines:self .catalog_number_set.add(js['catalog_number' ])self .json_file = open ('output.jsonl' , 'ab' )self .json_exporter = JsonLinesItemExporter(self .json_file, ensure_ascii=False , encoding='utf8' )self .json_exporter.start_exporting()def process_item (self, item, spider ):self .catalog_number_set.add(item['catalog_number' ])self .json_exporter.export_item(item)return itemdef close_spider (self, spider ):"""结束时自动执行一次""" self .json_exporter.finish_exporting()self .json_file.close()
在 computerhistory.py 开头加上:
1 from demo_project.pipelines import DemoProjectPipeline
改写 parse 方法:
1 2 3 4 5 6 7 8 def parse (self, response ):"https://www.computerhistory.org/collections" '//*[@id="content"]/div[3]/div/div/div/div/p/span[1]/a/@href' ).extract()for url in url_list:if url.split('/' )[-1 ] in DemoProjectPipeline.catalog_number_set: continue 2 :]yield scrapy.Request(url, callback=self .parse_item)
最后用以下指令执行:
1 $ scrapy crawl computerhistory
因为 pipeline 帮我们输出为文件了,所以我们不需要再在命令里输出了。