【论文翻译】Towards LLM-driven Dialogue State Tracking
【论文翻译】Towards LLM-driven Dialogue State Tracking
论文地址:Towards LLM-driven Dialogue State Tracking - ACL Anthology
摘要
在任务型对话(TOD)系统中,对话状态跟踪(DST)是确保用户意图和系统行为得到精确追踪的核心环节。随着以 GPT3 和 ChatGPT 为代表的大型语言模型(LLM)的崛起,它们在不同场景和任务中的表现引发了广泛关注。本研究对 ChatGPT 在 DST 中的性能进行了初步研究。评估结果展示了 ChatGPT 在此任务中的出色表现,为研究人员提供了关于其能力的深刻认识,同时也为对话系统的设计和优化提供了宝贵的方向。尽管 ChatGPT 的性能令人瞩目,但其也存在一些明显的局限性,如闭源性、请求限制、数据隐私问题和缺乏本地部署能力等。为了克服这些挑战,本文提出了 LDST,一个基于小型开源基础模型的 LLM 驱动的 DST 框架。通过采用创新的域时隙指令调优方法,LDST 实现了与 ChatGPT 相当的性能。通过对三个不同实验设置的综合评估,我们发现与之前的 SOTA 相比,LDST 在零样本和少样本设置中表现出了显著的性能提升。为了确保实验结果可以复现,我们还提供了源代码。
1 介绍
任务型对话(TOD)系统已成为协助用户完成各类任务的高效工具,例如苹果 Siri 和微软 Cortana。它们作为虚拟个人助理,为用户在机票订购、预约安排和酒店预订等方面提供了极大的便利。在这些系统中,对话状态跟踪(DST)发挥着至关重要的作用。它能够精准地追踪对话过程中用户意图和系统响应的不断变化。一般而言,多域对话状态通过 (domain, slot, value) 形式的三元组列表来表示,例如 "<restaurant, area, east>" 。这些预定义的槽(slot)在每个对话回合中都会从对话上下文中提取相关信息。
最新的研究针对多域(multi-domain)DST 挑战而提出了众多模型。这些模型的核心关注点是跨领域的有效迁移和泛化(transfer and generalization),特别关注于解决如图 1 所示的关键问题,即共指(co-reference)问题和误差传播(error propagation)问题。
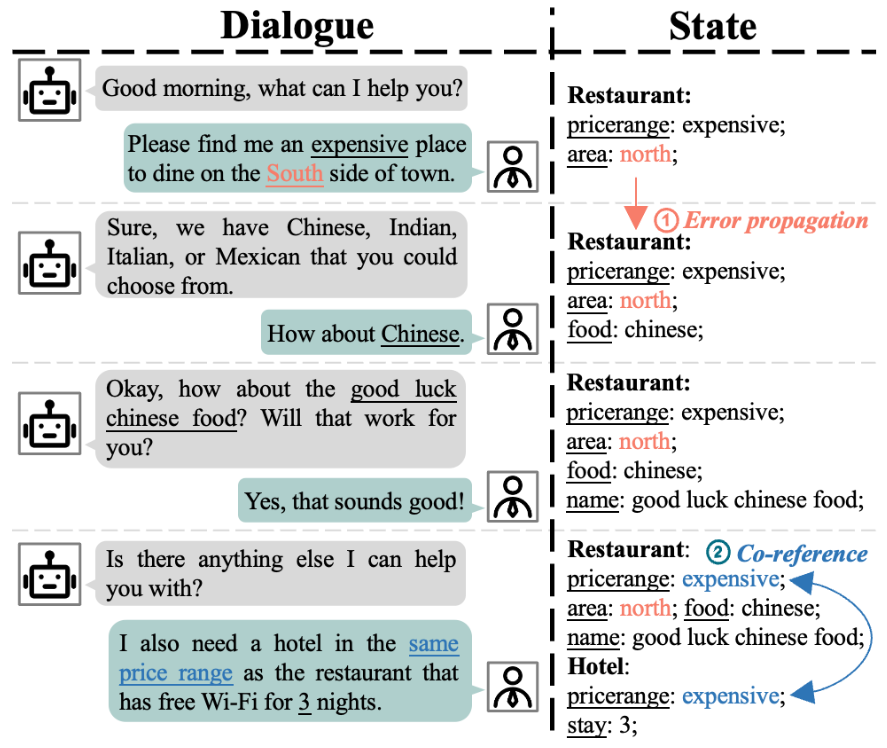
图1:一个多域对话的例子。在这个例子中,"hotel-pricerange" 和 "restaurant-pricerange" 这两个位置具有共指关系,意味着我们可以从后者的值推断出前者的值。另外,"restaurant-area" 这个槽位则展示了错误传播的问题。
共指问题是提高 DST 性能的一个重大障碍,因为这一问题源于多轮对话中的语境变化,其中槽和值往往被间接表达。此外,当模型未能识别并纠正先前预测的对话状态中的错误时,就会出现错误传播问题,从而导致错误在后续对话回合中持续存在。尽管为解决这些问题,人们已经付出了巨大努力,但它们仍然是当前面临的重要挑战。
近年来,随着大语言模型(LLM)的出现,自然语言处理(NLP)领域发生了翻天覆地的变化。这些模型,如 ChatGPT,展现出了卓越的性能,引起了人们对评估其在不同任务的能力的浓厚兴趣。尽管 LLM 在多个领域未来可期,但它们在多域对话状态跟踪(DST)中的表现仍然相对未被深入研究。为了弥补这一研究空白,我们对 ChatGPT 在 DST 任务上的能力进行了评估。评估结果显示,ChatGPT 在 DST 任务中展现出了卓越的性能,为研究人员提供了宝贵的启示,并为进一步探索提供了新的方向。
尽管 ChatGPT 表现出了卓越的性能,但它也存在显著的局限性。首先,作为一个非开源模型,其底层代码和模型参数并不允许用户进行修改,这在一定程度上限制了其灵活性。其次,由于存在请求限制,ChatGPT 在高需求场景中的使用受到了一定的制约。此外,由于系统可能会收集并存储用户数据,这也引发了对于数据隐私保护的担忧。最后,由于 ChatGPT 无法部署在本地,这进一步限制了其可用性和控制能力。这些限制因素共同阻碍了 ChatGPT 在构建 TOD 系统中的广泛应用。
为了克服 ChatGPT 的局限性,我们提出了 LDST ——一个由较小的开源大模型驱动的 DST 框架。LDST 采用了一种新颖的组合域槽指令调优(assembled domain-slot instruction tuning)方法和参数高效调优技术,使其能够在使用更小模型和有限计算资源的情况下达到与 ChatGPT 相当的性能。在三个不同的实验设置中,LDST 展现了卓越的性能,显著超越了 SOTA 方法,并表现出了强大的适应性和泛化能力。我们的主要贡献如下:
- 我们首次在 DST 任务中对 ChatGPT 进行了评估,结果显示其相较于之前方法具有卓越性能,并为推动对话系统的发展提供了贡献;
- 本文提出了一种基于较小开源基础模型的 LLM 驱动型 DST 框架,即 LDST。LDST 采用了一种创新的组合式域时隙指令调优技术,实现了与 ChatGPT 相当的性能表现;
- 经过在三个基准数据集上的广泛评估,LDST 在各种实验设置下均展现出了显著的性能提升。特别是在零样本场景中,LDST 将 JGA 分数提升了 16.9%,由原本的 65.3% 跃升至出色的 82.2%。在少样本情况下,LDST 同样表现出色,将 JGA 分数提高了 7.5%,由 47.7% 提升至显著的 55.2%。这些结果充分证明了 LDST 在对话状态跟踪任务中的卓越性能。
2 评估 ChatGPT 的 DST 性能
在本节中,我们将评估 ChatGPT 在 DST 任务方面的能力。在深入讨论之前,我们首先对问题进行正式定义。
DST: 问题表述
在 TOD 系统中,系统与用户之间的对话由 \(T\) 个回合组成,可以表示为一系列的 \(\{(A_1, U_1),(A_2, U_2), ..., (A_T, U_T)\}\) 对,其中 \(A\) 代表系统响应,\(U\) 代表用户输入。首先定义一个槽位集合 \(S = \{S_1, ..., S_J\}\),其中 \(J\) 为总槽数。第 \(t\) 轮的对话上下文包含了前几轮的交互信息,记作 \(\mathcal{X}_t = \{(A_1, U_1), (A_2, U_2), ..., (A_t, U_t)\}\)。第 \(t\) 轮的对话状态则是由一系列 (slot,value) 对构成的集合,记作 \(\mathcal{B}_t = \{(S_1, V^t_1), ..., (S_J, V^t_J)\}\),其中 \(V^t_j\) 为 \(S_j\) 槽位的值。
对于多域 DST,根据先前的工作,一个槽位被定义为特定域和槽的组合,例如 "<restaurant-area>"。如果在对话过程中没有提供关于特定槽位的信息,则该槽位的值会被设置为 NONE。从本质上讲,DST 问题可以被看作是一个学习对话状态跟踪器 \(\mathcal{F}:\mathcal{X}_t\to\mathcal{B}_t\) 的过程。
利用 ChatGPT 实现 DST
我们在三个多域 DST benchmark 上评估了 ChatGPT 的性能,通过利用 gpt-3.5-turbo API 服务进行实验,并使用 JGA 和 AGA 作为评估指标。如图 2 所示,我们探索了多种 prompt 模板,并在 MultiWOZ 2.2 数据集上选择了最佳的 prompt 模板以进行后续实验。
| Input | Expected Output | AGA | |||
|---|---|---|---|---|---|
| 1 | Single return | No demo | Perform the task of multi-domain dialogue state
tracking. The following is the dialogue you need to test: [dialogue context] Please return the value of the slot: <hotel-pricerange>. [the description of the slot and its possible value list] So the value of the slot <hotel-pricerange> is |
hotel-pricerange: Cheap | 95.52 |
| 2 | Multi return | No demo | Perform the task of multi-domain dialogue state
tracking. And the slot schema is in this list: ['hotel-pricerange', 'train-bookpeople', 'train-leaveat', ...]. The following is the dialogue you need to test: [dialogue context] Please return the value of slot list: [hotel-pricerange, train-bookpeople, train-leaveat, ...]. |
hotel-pricerange: Cheap, train-bookpeople: 2, train-leaveat: 14:00, ... |
81.50 |
| 3 | Single return | One demo | Perform the task of multi-domain dialogue state
tracking. I will show a example. Please return to the state of the slot The example dialog is [dialogua context] So the value of slot <hotel-pricerange> is Output result: Cheap The following is the dialogue you need to test: [dialogue context] Please return the value of the slot: <hotel-pricerange>. [the description of the slot and its possible value list] So the value of the slot <hotel-pricerange> is |
hotel-pricerange: Cheap | 91.93 |
| 4 | Multi return | One demo | Perform the task of multi-domain dialogue state
tracking. I will show a example.Please return the value of slot list: ['hotel-pricerange', 'train-bookpeople', 'train-leaveat', ...]. The example dialog is [dialogua context] Output result: Train-Departure: Norwich, Train-Arrival: Cambridge, hotel-pricerange: Cheap, ... The following is the dialogue you need to test: [dialogue context] Please return the value of slot list: [hotel-pricerange, train-bookpeople, train-leaveat, ...]. |
hotel-pricerange: Cheap, train-bookpeople: 2, train-leaveat: 14:00, ... |
73.33 |
图 2:在 MultiWOZ 2.2 测试集上使用的不同 prompt 模板和相应的结果
在上表中,"single return" 和 "multi return" 分别指的是每个 ChatGPT API 请求所返回的槽值的数量。具体而言,"single return" 指的是一次请求只返回一个槽的值,而 "multi return" 则指的是一次请求同时接收所有槽的值。以拥有 49 个不同槽的 MultiWOZ 2.2 数据集为例,"multi return" 可以在一个请求中一次性检索到所有 49 个槽的值。虽然这种方式减少了 API 请求的次数,但每个请求的 token 数量却相应增加。相反,"single return" 则会显著增加 API 请求的次数,但它简化了模型的任务,从而有助于提高性能。此外,"no/one demo" 表示是否在 prompt 中提供一个示例作为演示,这有助于模型更好地理解任务。选择 "one demo" 类似于采用上下文学习的概念。
关于详细的 prompt 模板设计,请参见附录 A.1。
ChatGPT 的表现
从图 2 可以观察到,在输入中未包含 demo 的情况下,第一个 prompt 通过检索每个请求中单个槽的值,取得了最高的 AGA 分数。主要因为要求模型在单个请求中提供多个槽值还是有难度的。我们注意到,ChatGPT 有时会错误地预测某些位置的值应为 NONE。例如在 hotel-leaveat 这个位置,正确答案应该是 14:00,但ChatGPT 可能会错误地预测为 NONE,这导致预测精度的降低。另外,尽管在输入中添加 demo 通常会提高效果,但在此情况下却产生了相反的效果,这似乎有些反直觉。然而,通过深入分析错误结果,我们发现是由于 demo 和测试样本存在明显差异导致对 ChatGPT 的干扰。因此,基于上述分析,我们选择了第一个 prompt 作为后续评估的最佳模板。
经过在三个数据集上的全面评估,ChatGPT 的表现如图 3 所示。在 SGD 数据集上,ChatGPT 的 AGA 得分显著超越了先前的 SOTA 方法,实现了 7.46% 的绝对提升。同时,在三个数据集上,JGA 得分的平均提升为 0.73%,而 AGA 得分的平均提升更是高达 2.34%。尽管在 MultiWOZ 2.2 数据集上,ChatGPT 的性能略逊于先前的 SOTA 方法,但经过对错误的深入分析,我们发现其中 70% 的错误是由于原始数据集的标注问题。因此,在修正了标注错误的 MultiWOZ 2.4 数据集上,ChatGPT 的表现超越了 SOTA 方法。
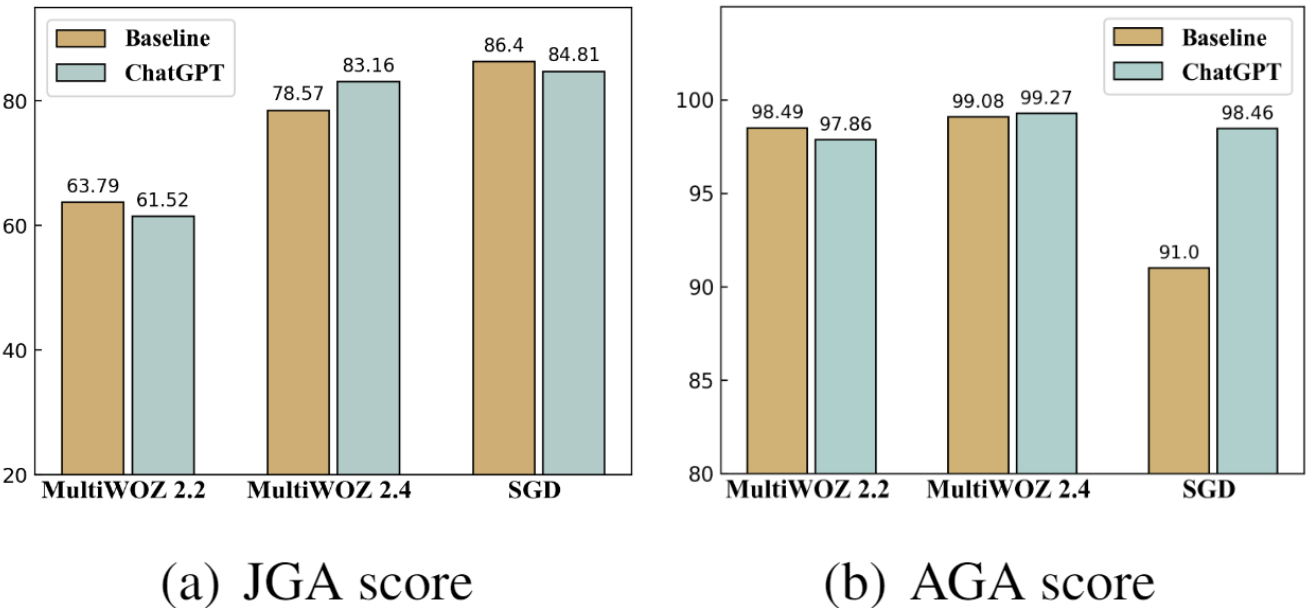
图 3:best baseline 和 ChatGPT 在多个数据集上的实验结果。JGA 和 AGA 指标值越高越好。
ChatGPT 的局限
综上所述,尽管 ChatGPT 在解决 DST 任务时展现出了与先前 SOTA 方法相当的性能,突显了当前 LLM 在多轮对话中捕捉和理解复杂语言模式和依赖关系的能力,但其仍存在几个显著的局限性,从而限制了在各种实际场景中的应用和采用。首先,我们注意到 ChatGPT 经常返回大量解释性内容,或者其答案可能与我们的预期格式不完全一致。例如,当正确答案值为 2 pm 时,ChatGPT 可能会返回 14:00。尽管两者在本质上都是正确的,但这种表达方式的差异可能会影响最终评估指标的准确性。其次,ChatGPT 是非开源的,这限制了开发人员和研究人员修改和定制模型的能力。此外,由于存在请求限制,ChatGPT 可能不适用于需要即时或大规模响应的实时应用程序。再者,由于 ChatGPT 在云环境中运行且缺乏严格的数据隐私保护措施,引发了关于对话中敏感信息共享时的隐私和安全问题的担忧。最后,由于 ChatGPT 依赖于互联网连接,它无法在本地进行部署,这进一步限制了其可用性和控制能力。
3 用 DST 指令对较小的基础模型进行微调
为了克服 ChatGPT 的上述限制,本文提出了一种名为 LDST 的 LLM 驱动的 DST 框架。该框架采用较小的开源基础模型进行微调,如 LLaMa,并且针对 DST 任务进行了特别的定制。首先,我们概括了为多域 DST 任务构建指令数据集的过程。然后,利用参数高效微调(PEFT)技术,我们使用该指令数据集对基础模型进行训练。PEFT 技术的优势在于,它能够在有限的计算资源下有效地训练基础模型。通过这种方法,LDST 旨在提高 DST 任务的性能和效率。
3.1 指令调优
与上下文调优相比,指令调优(instruction tuning)为模型提供了更加明确而详细的定制,这些定制是通过特定任务的指令来实现的。这种调优方式使得对模型行为的控制更加精细,进而在性能上超过了上下文调优。指令调优的核心在于设计指令数据集,该数据集通常包含说明、输入和输出字段。在实际应用中,不同的任务通常会采用不同的说明。然而,对多域 DST 使用固定的指令模板可能会限制模型的稳定性,这突显了指令设计在模型性能中的关键作用。
为了应对这一挑战,我们提出了一种新的用于 DST 任务的组装域-槽指令生成方法。该方法通过随机组合不同的指令和输入模板来生成多样化的指令样本,从而在微调过程中使模型能够接触到丰富的指令类型,降低模型对特定 prompt 的敏感性。如图 4 所示,对于原始数据集中的每个样本,它都包括对话上下文 \(\mathcal{X}_t\)、当前请求的槽 \(\mathcal{S}_J\) 及其对应的状态 \(V^t_J\)。接着,我们通过指令数据生成模块将原始数据转化为指令样本。下面将详细介绍每个字段的模板设置。
说明 Prompt
具体来说,我们定义了两种指令模板:(1)标准槽跟踪指令(2)自定义槽跟踪指令。二者之间的主要区别在于,自定义槽跟踪指令提供了更为具体的域槽信息。在生成指令样本时,每个样本的说明字段从这两种模板中随机选择。
输入 Prompt
对于输入字段,我们设计了一个 prompt 模板,它由四个核心部分构成:(1)对话上下文(2)域槽描述 prompt(3)可能值列表(PVL)prompt 以及(4)查询 prompt。图 4 中示例中的绿色、紫色、蓝色和橙色文本分别指的是这四种 prompt。特别的,我们使用表示系统语句(system utterance)起始的 token(例如 [USER])将所有子序列连接起来。域槽描述 prompt 和 PVL prompt 都是对需要跟踪的槽位的补充描述,这些描述直接来源于原始数据集中的预定义模式(需要注意的是,PVL prompt 符仅适用于可枚举的槽)。为了模拟在测试阶段模型可能无法获取到请求槽位的描述或可能值的情况,我们在生 prompt 模板时,以 50% 的概率随机地包含这两个部分。这样设计旨在提高模型的稳定性,使其能够在不完整的 prompt 信息下仍然能够有效地进行对话状态跟踪。
输出 Prompt
最后,输出字段由请求槽 \(S_J\) 的对应值 \(V^t_j\) 组成。经过上述步骤,我们成功地构建了一个新颖且多样化的指令数据集,这将为接下来的模型微调阶段提供有力的支持。
3.2 参数高效微调
在本节中,我们将详细介绍如何利用参数高效方法微调基础模型。具体来说,LDST 框架将指令和输入字段作为输入,并从数据集中检索出相应的槽值 \(V^t_J\) 作为输出: \[ V^t_J=Decoder(\hat{\mathcal{X}}) \] 其中,Decoder 代表基础模型(如 LLaMa),该模型采用 Transformer-decoder 框架。\(\hat{X}\) 代表指令数据,比如指令和输入字段的组合。
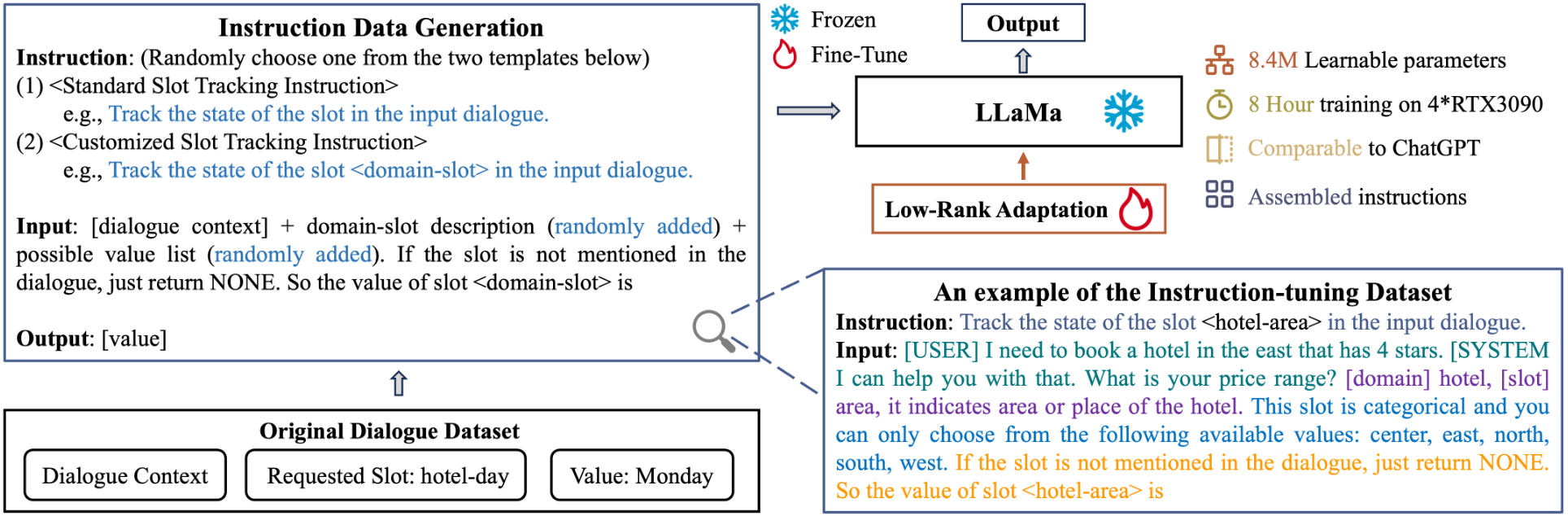
图 4:LDST 模型的结构。第一步,我们利用指令数据生成模块,从原始数据集中构建出指令数据集。随后,我们运用参数高效微调技术,基于该指令数据集对基础模型进行训练。
为了提升微调过程的效率和降低内存需求,我们采用了低秩自适应(LoRA)方法,如图 4 所示。在 LoRA 中,预训练的模型权重被冻结,而将可训练的秩分解矩阵注入到 Transformer 架构的每一层中。这一方法显著减少了下游任务的可训练参数数量。例如,在针对 LLaMa 7B 的实验中,仅需要学习 8.4M 的参数,这仅占模型总参数的 0.12%。这些可训练参数可以表示为权重矩阵 \(W_0\in \mathbb{R}^{d\times k}\)。与传统的直接修改 \(W_0\) 值的方法不同,LoRA 引入了一组额外的可训练参数,记为 \(\Delta W\),它们直接注入到原始 \(W_0\) 中。我们将这种更新表示为 \(W = W_0 + \Delta W = W_0 + BA\),其中 \(B\in \mathbb{R}^{d\times r}\),\(A \in \mathbb{R}^{r\times k}\),且秩 \(r \ll min(d, k)\)。在训练过程中,\(W_0\) 保持冻结,不接收任何梯度更新,而我们只更新 \(A\) 和 \(B\) 中的参数。需要注意的是,\(W_0\) 和 \(\Delta W = BA\) 都与相同的输入相乘,并对各自的输出向量进行坐标求和。对于原始输出 \(h = W_0x\),LoRA 修改后的正向传递结果如下: \[ h = W_0 x + \Delta Wx = W_0 + BAx \] 最后,在 LDST 框架中,生成过程的学习目标是在给定上下文 \(\mathcal{X}_t\) 和槽 \(S_J\) 的条件下,最小化 \(V^t_J\) 的负对数似然: \[ L = -\sum\limits^{T}_{t}\sum\limits^{J}_{j} \log p(V^t_j|\mathcal{X}_t, S_{j}) \]
4 实验
4.1 数据集
我们利用多领域 TOD 的基准数据集进行了实验,并在表 1 中展示了这些数据集上的详细统计信息。
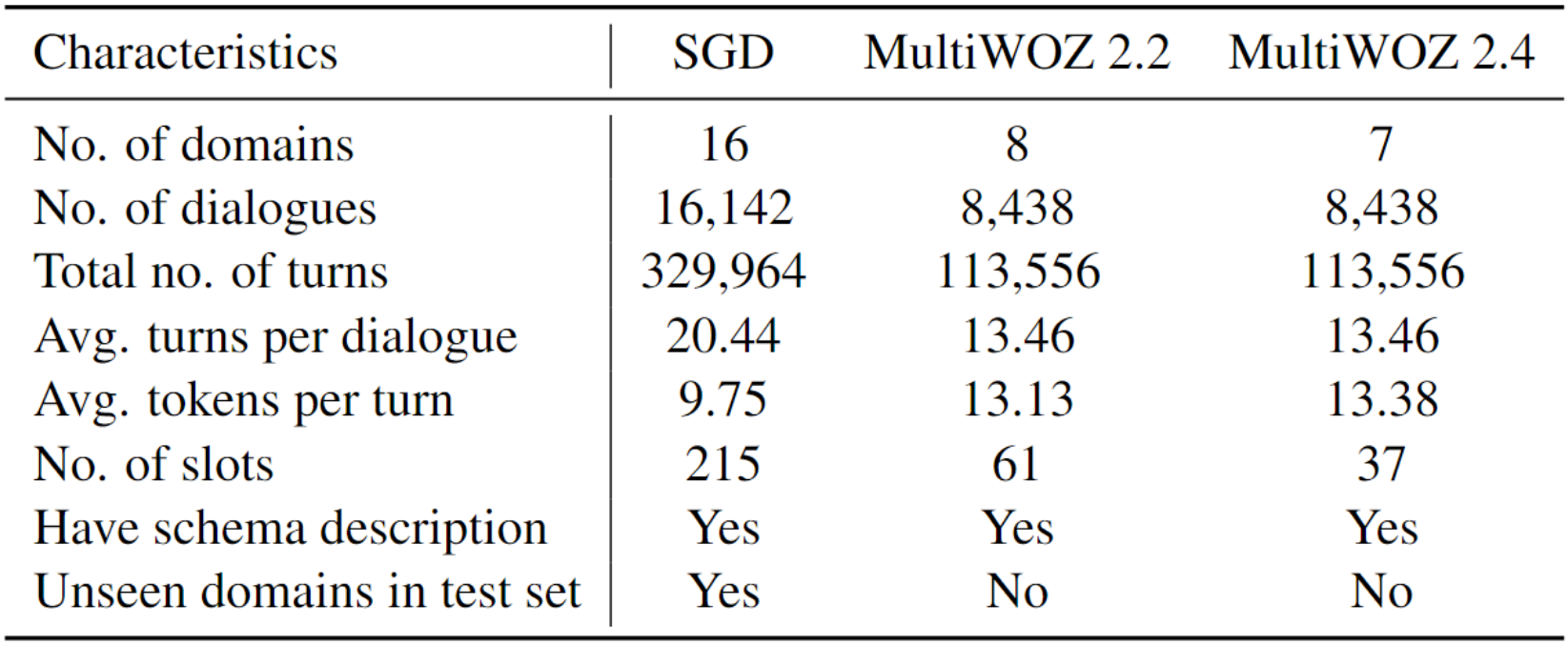
表 1:实验中训练用到的数据集的统计信息
Schema-Guided Dialogue(SGD)
SGD 是一个极具挑战性的数据集,包含了超过 16,000 个人类用户和虚拟助手之间的对话。这个数据集涵盖了 16 个不同领域的 26 种服务,如事件、餐馆和媒体等。值得注意的是,SGD 在其测试集中引入了未见的域,这对模型的泛化能力构成了巨大的挑战。
MultiWOZ 2.2 and MultiWOZ 2.4
MultiWOZ 2.4 是MultiWOZ 2.2 的更新版本,专注于改进 DST 评估。MultiWOZ 2.4 的验证集和测试集已经过精心地重新标注,因此,我们将其视为用于测试的干净数据集。同时,我们还在已知存在注释噪声的 MultiWOZ 2.2 上进行了实验。这一嘈杂的数据集旨在测试模型的稳定性,并分析模型在检测测试集中注释错误的能力。
4.2 评测指标
我们采用了与之前工作相一致的评估指标,具体包括联合目标准确度(JGA)和平均目标准确度(AGA)。JGA 作为 DST 评估的主要指标,反映了正确预测整个状态对话轮次的比率。而 AGA 则是指每轮活跃槽的平均准确率。当槽的值在当前回合中被提及且并非继承自之前的回合时,该槽将被视为活跃状态。
4.3 主要结果
我们对 LLM 驱动的 LDST 模型在三个不同的实验设置下进行了全面的评估,发现该模型在零样本和少样本设置中均展现出了显著的性能提升。这些发现对于 DST 领域的研究具有重要的推动作用,并为研究界提供了宝贵的见解和贡献。以下是具体的实验结果:
零样本多域实验结果
按照之前的零样本设置,所有模型首先在特定领域进行训练,然后在未见域的测试集上进行评估。在此过程中,我们将我们 baseline 模型与一系列能够预测未见域对话状态的先进方法进行了比较,包括 SGD-baseline、TransferQA、SDM-DST、SUMBT、SimpleTOD、T5DST 以及 D3ST 方法。
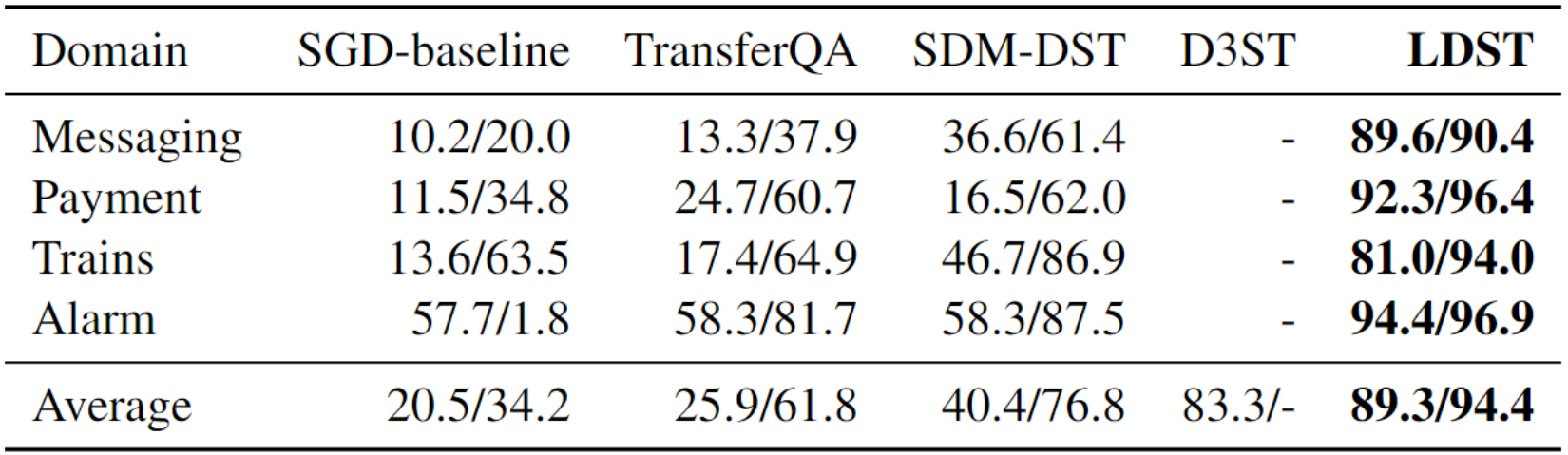
表 2:SGD 数据集上的零样本结果(JGA(%)/AVG(%))
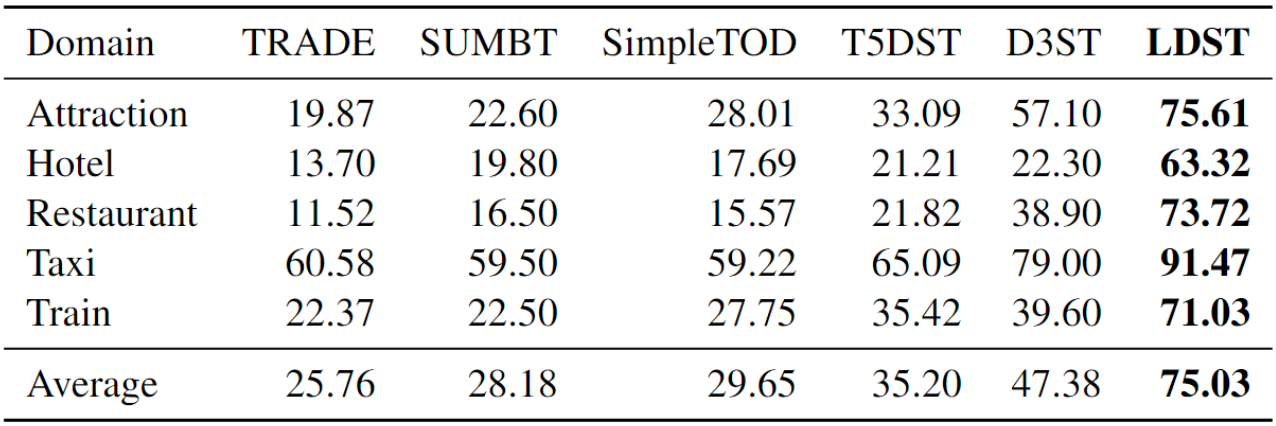
表 3:MultiWOZ 2.0 上的零样本结果(JGA(%)/AVG(%))
表 2 和表 3 清楚地展示了我们的方法在零样本跨域 DST 中的卓越表现。具体来说,在 SGD 数据集上,与基于大型 T5-XXL(11B)的 D3ST 模型相比,我们的 LDST 模型在 JGA 分数上实现了显著的 6.0% 绝对增长,从 83.3% 提升到了惊人的 89.3%。此外,AGA 分数也经历了 17.6% 的大幅增长,从 76.8% 增加到了显著的 94.4%。这些结果充分证明了我们的方法在处理零样本跨域 DST 任务时的有效性。
在 MultiWOZ 2.0 数据集上,我们观察到平均 JGA 分数有了显著的提升,从 47.38% 上升到 75.03%,这意味着 27.65% 的绝对提升。特别值得一提的是,SGD 数据集在支付领域表现出了最为突出的进步,JGA 指标从 24.7% 飙升到惊人的 92.3%。这种显著的进步可以归因于支付领域与原域的独立性。这一重要提升不仅充分展示了 LDST 模型强大的迁移学习能力,而且还突显了它对 DST 研究社区的重要影响。
少样本结果
在少样本设置下,我们参考了前人的多域场景,随机选取了 1%、5% 和 10% 的训练对话数据进行训练,并在每个域的完整测试集上进行了评估。MultiWOZ 2.4 的评估结果如表 4 所示,我们将其与当前最先进的少样本 DST 方法进行了比较,包括 DS2-BART、DS2-T5、IC-DST GPT-Neo 以及 SM2-11b。
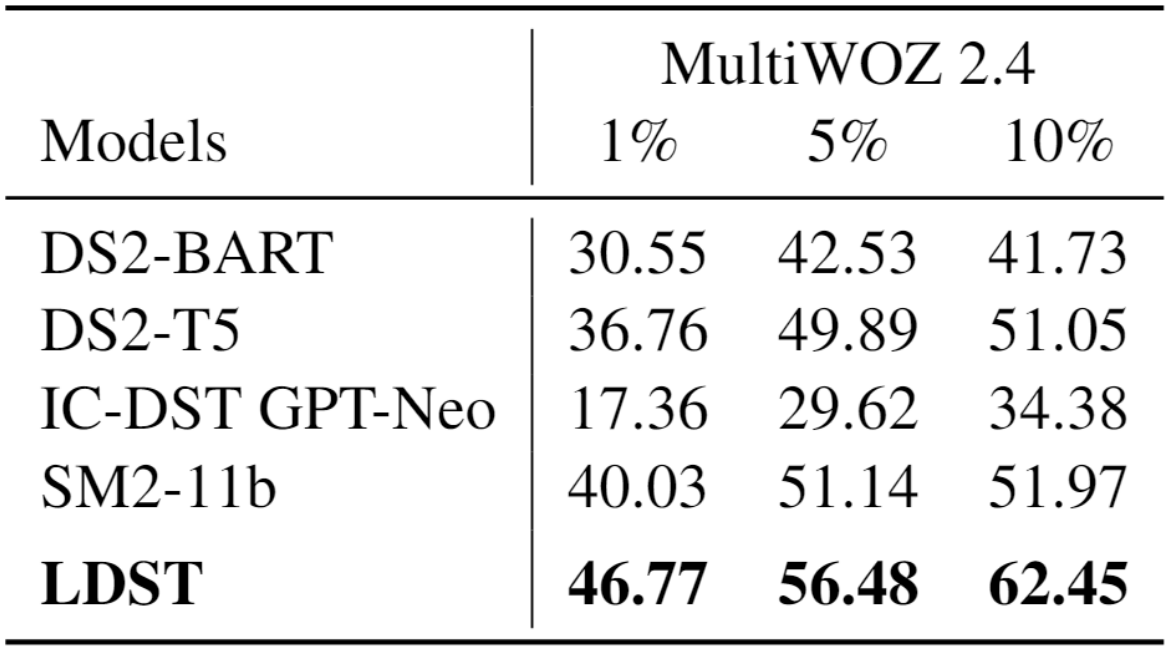
表 4:MultiWOZ 2.4 上少样本实验的 JGA(%)
结果表明了一个清晰的趋势:随着训练数据量的增加,各模型的性能均呈现出持续的提升。值得一提的是,我们的 LDST 模型在此设置下表现尤为出色。在 10% 的数据设置下,我们的模型显著提高了 JGA 指标,从 51.97% 提升至 62.45%,实现了高达 10.48% 的提升。即使在仅使用 5% 数据的设置下,我们的方法也超过了使用 10% 数据的传统方法。这充分展示了 LDST 模型在学习能力方面的卓越表现,以及其在利用较小数据集捕捉任务核心方面的强大能力。
全训练集微调结果
我们进一步使用完整的训练数据集来评估 LDST 模型的性能,并将其与一系列强大的 baseline 模型进行了比较。这些 baseline 模型包括 SGDbaseline、TRADE、DS-DST、TripPy、Seq2Seq-DU、MetaASSIST、SDP-DST、TOATOD、DiCoSDST、D3ST 以及 paDST。具体的评估结果如表 5 所示。
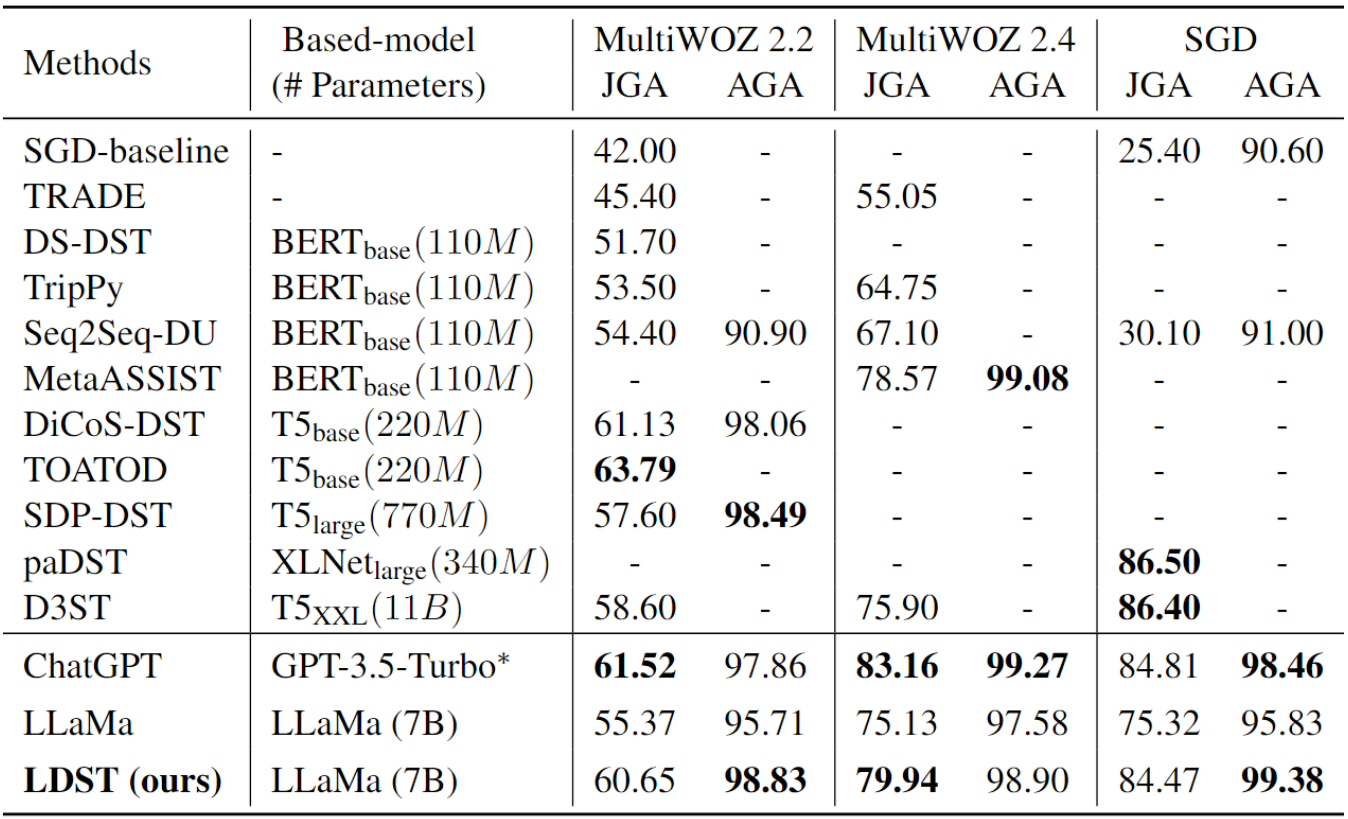
表 5:使用完整训练数据进行微调的结果。- 表示原始论文中没有报告结果。* 表示参数的准确值是不确定的,但绝对超过 100 亿。
我们最初关注到的是近期 LLM(如 ChatGPT 和 LLaMa)所取得的显著进步。令人瞩目的是,我们所提出的模型与 ChatGPT 实力相当,甚至在 SGD 数据集上实现了超越,特别是在 AGA 指标上,其得分超过了 98%,表现卓越。
目前,paDST 方法在 SGD 数据集上展现了 SOTA 的性能,其 JGA 得分达到了 86.5%,超过了 LDST 的 84.47%。然而,值得注意的是,paDST 的成功依赖于额外的技术,包括英文和中文之间的回译用于数据增强,以及针对模型预测的特殊人工规则。相比之下,LDST 仅依赖于 SGD 数据集的默认设置,无需额外辅助工具。另一种表现优异的 SOTA 方法是 D3ST,它采用 T5-XXL 作为骨干模型,具有 11B 参数(请参见附录 B,以了解 LDST 基于不同基础模型和不同模型大小的结果)。在 SGD 数据集上,D3ST 的性能超过了 LDST。然而,值得注意的是,LDST 在 Multiwoz 2.2 和 2.4 上的表现优于 D3ST。此外,与 LLaMa 核心模型相比,我们的模型证明了改进的有效性,进一步强调了在当前研究中微调 LLM 的重要性。
跨数据集迁移结果
为了评估模型的跨数据集迁移能力,我们参照了论文中表 4c 中描述的实验设置进行了进一步的实验。实验结果如表 6 所示,其中 LDST 的跨数据集迁移能力得到了突显。与 D3ST 方法相比,LDST 在 JGA 方面平均提高了 2.7%,显示出其出色的跨数据集性能。

表 6:SGD 和 MultiWOZ 2.4 跨数据集迁移的结果 JGA(%)
4.4 消融实验
为了验证组合式域时隙指令调优的实际效果,我们将其与传统的指令调优方法进行了对比分析。传统的指令调优方法通常依赖一个固定的 prompt 模板,该模板涵盖了所有请求时隙的描述(详见附录 A.2)。通过对比实验,我们发现我们的方法在性能上优于传统的指令调优。具体来说,如表 7 所示,我们的方法在 JGA 得分上显著提高了 2.15%,同时在 AGA 得分上也实现了 1.06% 的提升。这些结果充分证明了组合式域时隙指令调优的有效性。
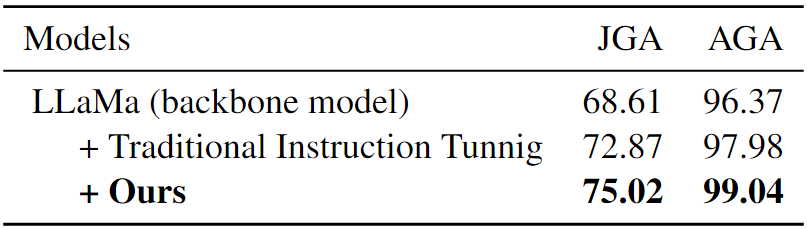
表 7:消融实验。Multiwoz 2.2、Multiwoz 2.4 和 SGD 上的平均 JGA(%) 和 AGA(%)。
为了分析模型在测试阶段对不同 prompt 的敏感性,我们精心设计了六种不同的 prompt,并评估了它们各自的效果。如图 5 所示,实验结果清晰地展示了 LDST 在测试中的卓越表现。与其他两种 baseline 方法相比,LDST 不仅准确率显著提高,而且表现出了更低的方差。特别是在与 LLaMa 模型的对比中,我们的方法平均方差仅为 0.04,而 LLaMa 模型的平均方差为 0.78,这意味着我们的方法使方差大幅下降至 0.74。这些发现充分证明了通过组装技术进行指令调优可以有效地降低模型对 prompt 的敏感性,从而提供了更稳定、更有效的推理过程,并增强了模型的整体的稳定性。
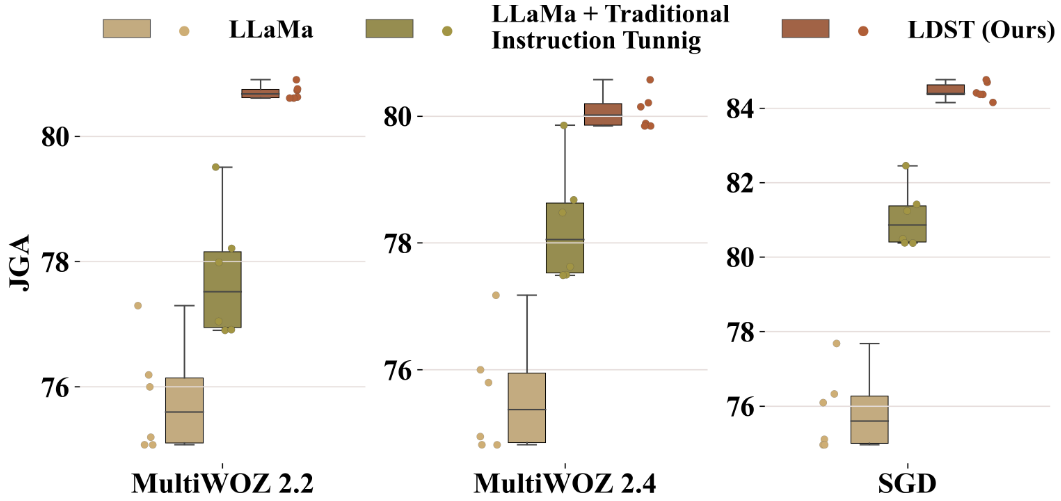
图 5:在测试阶段比较模型对不同 prompt 的敏感性
4.5 错误分析
为了深入分析 LDST 中的错误预测类型,我们观察了 MultiWOZ 2.4 数据集中的 2835 个错误预测样本。初步分析显示,45.72% 的错误与 dontcare 和 not mentioned 这两个值有关。例如,当基本事实为 dontcare 时,模型却预测为 not mentioned,或者相反。进一步探究发现,在错误率最高的前五个槽位中,分别是 hotel-type(338个错误)、restaurant-name(290个错误)、hotel-area(225个错误)、hotel-name(221个错误)和 attraction name(205个错误),这五个槽位的错误合计占据了总错误率的 45.11%。具体到 hotel-type 槽位,我们发现有 78.10% 的错误是由于模型经常将 not mentioned 与 hotel 这两个值混淆所致。例如,当 hotel-type 的正确值应为 hotel 时,模型却错误地预测为 not mentioned。
4.6 LDST 在解决 DST 难题方面的作用
为了评估共同参考挑战的性能,我们深入分析了 MultiWOZ 2.3 数据集,该数据集包含了 253 个带有共指关系注释的测试样本。通过评估,我们发现最佳的 baseline 方法实现了 91.1% 的准确率。相比之下,我们的 LDST 模型展现出了令人瞩目的性能,达到了 96.4% 的准确率。这一结果充分证明了我们的方法在共同参考挑战上的显著优势和改进。
此外,我们还通过图 6 对每个对话轮次的 JGA 分数进行了可视化展示,以进一步验证我们模型在解决错误传播问题上的有效性。从结果中可以明显看出,随着对话轮数的增加,所有方法的性能都会不可避免地出现下降。然而,相比之下,我们的 LDST 模型表现出了显著的错误传播弹性,与 LLaMa 和最佳 baseline 方法相比,其性能下降的速度明显较慢。这一结果充分展示了 LDST 模型在多轮对话中捕捉和理解复杂语言模式和依赖关系的能力,使其成为应对DST任务相关挑战的有前景的解决方案。
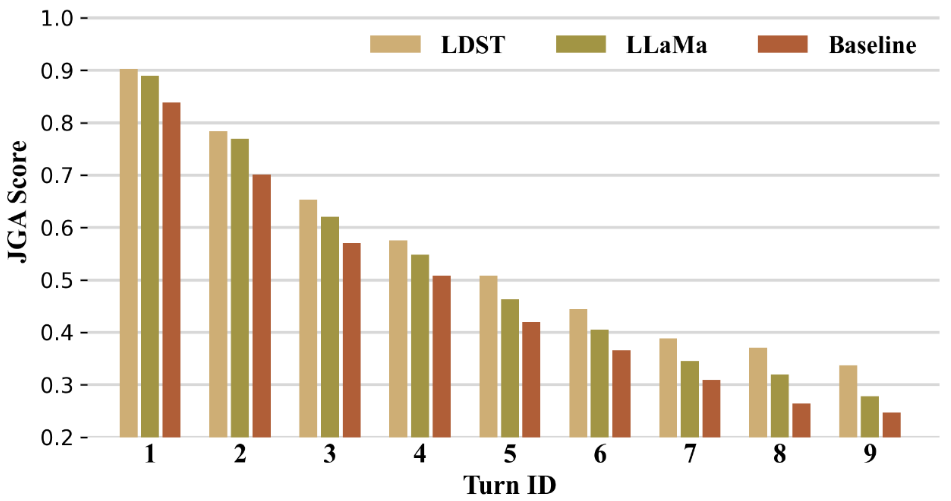
图 6:MultiWOZ 2.2 中每一轮的 JGA
5 相关工作
5.1 多领域 DST
近期,多域 DST 的研究取得了显著进展,主要得益于预训练语言模型的广泛应用。例如,Xie 等人(2022)提出了一种多阶段可校正对话状态跟踪方法,旨在减轻错误传播现象;Wang 和 Xin(2022)则通过联合决策和对话更新技术来防止错误积累。此外,Wang 等人(2022a)和 Manotumruksa 等人(2022)还尝试通过学习槽之间的相关性来解决共同引用挑战,如采用槽提示或硬复制机制的组合。然而,这些方法仍然存在一些局限性,如处理复杂对话上下文时的稳定性不足,以及难以准确捕获槽和值之间的细粒度语义关系。
5.2 大模型 DST
尽管大型语言模型如 GPT-3(2020) 和 T5(2020) 已经获得了广泛的关注和应用,但如何有效利用这些模型仍然是一个重要的问题。参数高效微调(PEFT)技术的最新进展,如 LoRA(2021) 和前缀调整(2021),为解决这一挑战提供了有效的途径。例如,Lee 等人(2021)和 Yang 等人(2023b)分别提出了一种提示调优方法,通过利用特定领域的提示和上下文信息来增强 DST 任务的性能。同时,Ma 等人(2023)和 Chen 等人(2023)引入了前缀调优方法,通过在对话开始时添加特定标记来修改输入提示,旨在提高模型微调的效率。然而,这些方法仍然面临挑战,因为它们的效果在很大程度上取决于提示的设计。
近期,Heck 等人(2023)仅在 Multiwoz 2.1 数据集上评估了 ChatGPT 的性能。与之不同,我们的评估范围更加广泛,涵盖了 Multiwoz 2.2、2.4 以及 SGD 数据集,从而提供了更为全面的评估结果。尽管 Pan 等人(2023)和 Hudeček 与 Dušek(2023)的研究也包含了 Multiwoz 2.2、Multiwoz 2.4 和 SGD 数据集上的结果,但由于他们采用了 text-davci-003 API,导致其结果相对较低。而我们则采用了最新的 gpt-3.5-turbo API,这是一个经过优化、功能强大的 gpt-3.5 模型,不仅提高了聊天性能,还降低了成本。因此,我们成功实现了基于 ChatGPT 的新 SOTA 性能,并充分展示了其显著优势。
随着开源大型语言模型,如 LLaMa(2023)的涌现,这些模型提供了一系列高质量的主干模型,涵盖了不同的参数选择。研究表明,结合 LLaMa 与指令微调技术可以显著提升性能,这为我们的研究开辟了新的方向。
6 结论
本研究初步探讨了 ChatGPT 在多域 DST 中的应用能力,并展示了其相较于以往方法的优越性。这一综合评估为研究人员在设计和优化对话系统方面提供了有益的指导。为克服 ChatGPT 的局限性,我们提出了 LDST 这一基于小型开源基础模型的 LLM 驱动 DST 框架。通过运用创新的组装域槽指令调整方法,LDST 在性能上与 ChatGPT 相媲美。对三种不同实验设置的全面评估显示,LDST 相较于以前的方法实现了显著的性能提升。
局限
本文的工作存在两个主要限制:首先,关于 prompt 设计的主观性。尽管提示工程在大型语言模型的应用中展现出了巨大的潜力,但我们在研究中所采用的 prompt 设计却带有主观性,无法确保使用的一定是最佳的。因此,使用这些 prompt 对模型进行微调或测试的有效性可能并不总是能达到最佳效果。探索更系统的自动化技术来改进提示设计,有望提高模型的整体性能。其次,输入长度的约束也是一个需要考虑的问题。在我们的研究中,我们将模型的输入长度设定为 512,这是通过统计分析得出的,能够覆盖超过 90% 的样本。虽然增加输入长度是可行的,但这可能会导致训练和推理时间的增加。此外,当对话或描述内容变得过长时,如何有效地截断或总结输入就成了一个挑战。因此,进一步研究如何在不影响模型效率的前提下处理较长的输入序列,将是非常有益的。
A Prompt 模板描述
A.1 ChatGPT 请求的 Prompt 模板
最初,我们注意到 Pan 等人研究报告的结果。与我们的结果相比,Hudček 与 Dušek 的结果明显更低。我们原因主要有以下两点。
优化了答案过长的问题
我们发现 ChatGPT 经常给出过于详细的答案,这不符合预期的响应格式。例如,当询问 train-leaveat 槽时,ChatGPT 可能会提供诸如“第一辆火车的出发时间为 Monday at 05:16,而最后一个火车在周一离开”等详尽信息,而实际需要的正确答案仅为 05:16。为了解决这一问题,我们引入了一个包含 "No explanation!" 指令的提示,以指导 ChatGPT 避免提供详细的解释。实验结果显示,采用这种方法后,答案的准确性得到了显著提高。
API 版本变化
另一个影响因素在于使用了不同的 API 版本。先前的研究主要依赖于 text-davinci-003 API,而我们则选用了更加强大的 gpt-3.5-turbo API。这是一个具备高度能力的 GPT-3.5 模型,针对聊天功能进行了优化,并且相较于其他模型,其成本更低。
下面是我们为图 2 中的四种不同的 prompt 提供特定的示例。
Prompt 类型 1: "single return" + "no demo"
1 | |
Prompt 类型 2: "multi return" + "no demo"
1 | |
Prompt 类型 3: "single return" + "one demo"
1 | |
Prompt 类型 4: "multi return" + "one demo"
1 | |
出于与 API 请求成本相关的实际考量,我们选择在 MultiWOZ 2.2 数据集上仅使用这四个提示模板进行测试。随后,在 MultiWOZ 2.4 和 SGD 数据集上的评估工作,我们使用表现最为出色的模板组合,即 "single return" + "no demo"。
A.2 “传统”指令微调的 Prompt 模板
在此,我们介绍了传统指令微调的模板。这里的“传统”指的是将指令微调直接应用于具有固定 prompt 模板的 DST 任务。重要的是,这个固定的 prompt 模板涵盖了所有的槽描述,例如域槽描述和潜在值列表。无论是微调阶段还是测试阶段,都会采用这种固定的提示 prompt。
1 | |
B 额外发现
B.1 ChatGPT 与零样本方法的对比
本质上,ChatGPT 的评估属于零样本设置。尽管如此,鉴于我们发现 ChatGPT 的表现与传统的微调方法相近,我们在本文中将其结果显示在表 5 中。此外,我们还引入了在零样本设置下 ChatGPT 的结果,具体如表 8 和表 9 所示。
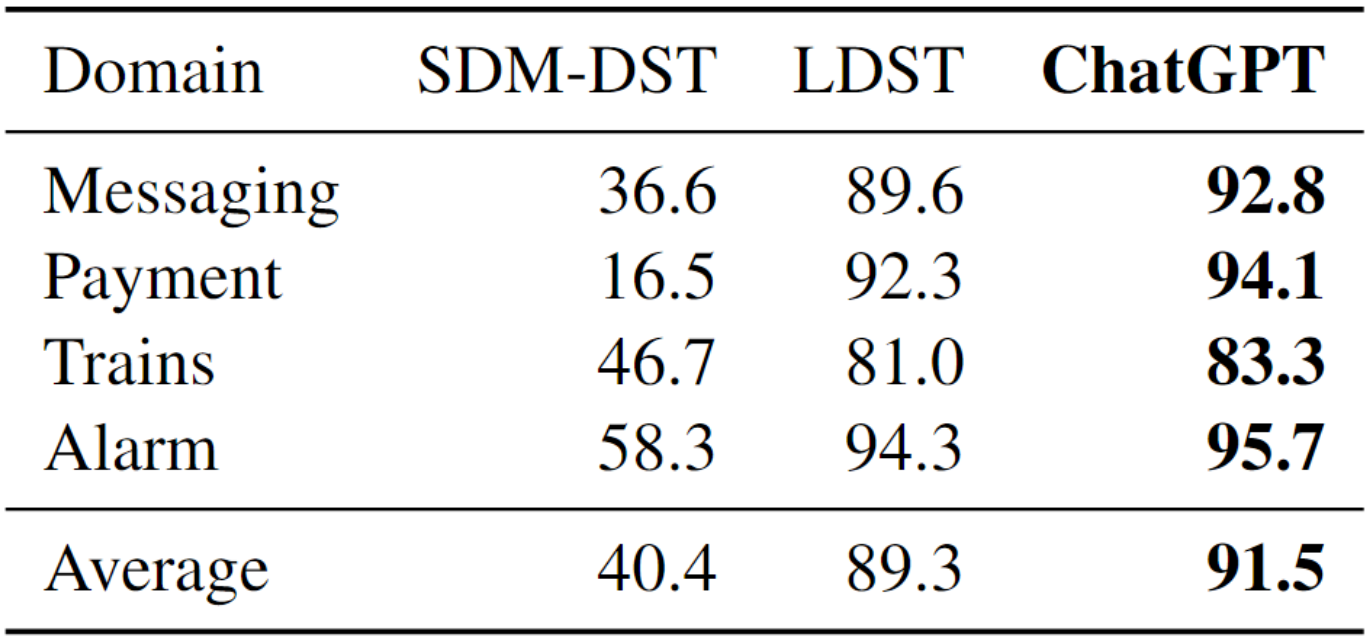
表 8:ChatGPT 在 SGD 数据集上的零样本 JGA(%)
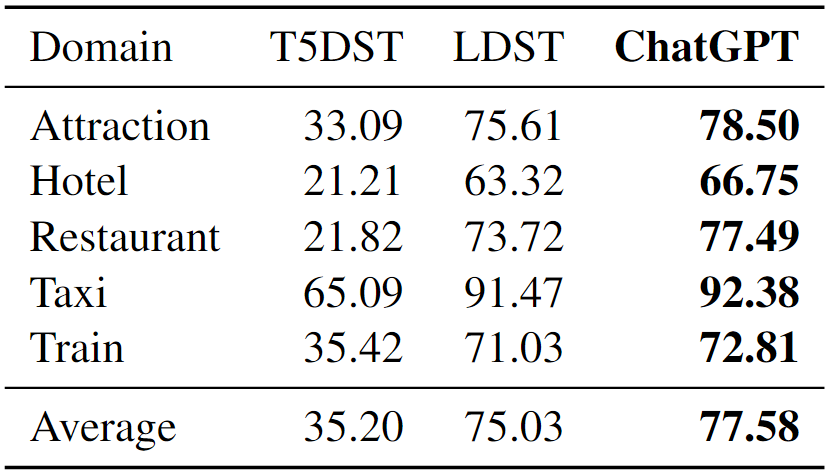
表 9:ChatGPT 在 MultiWOZ 2.0 上的零样本 JGA(%)
结果显示,ChatGPT 的性能明显超过了两个强大的 baseline 模型 SDM-DST 和 T5DST。这主要是因为评估是在零样本环境中进行的,这种环境下 ChatGPT 具有天然的优势。需要注意的是,作为一款 API 服务,ChatGPT 无法进行离线调优,仅适用于测试场景。
在零样本设置下,由于缺乏针对特定领域的训练数据,传统方法(如 SDM-DST 和 T5DST)的表现通常较差。然而,由于具备庞大的模型规模和丰富的预训练知识,ChatGPT 的性能大大超越了这些传统方法,并在零样本设置中达到了性能的上限。值得一提的是,ChatGPT 的性能甚至接近于在完整训练数据集上微调过的传统方法。因此,在表 5 中,我们将其纳入比较范围,以更全面地展示其性能表现。
相比之下,我们的 LDST 方法采用了定制的指令微调策略,成功地在零样本实验中接近了 ChatGPT 的性能表现,其 JGA 分数的平均性能差异仅为 2.4%。
B.2 不同基础模型的差异
为了进一步评估,我们将基础模型更换为 Llama2-7B,相关结果如下表 10 所示。

表 10:不同基础模型的 JGA(%)
研究结果表明,LDST_LLaMa2 在 SGD 上的表现最为出色,达到了 85.1% 的 JGA 得分,并展现了与 MultiWOZ 2.4 上的 ChatGPT 相似的性能。这一发现表明,使用更强大的主干模型可以提升 DST 的性能表现。
B.3 不同规模的 LLaMa 的实验结果
为了深入研究模型大小对性能的影响,我们在 SGD 数据集上结合了涉及 LlaMa-13B 和 LlaMa-30B 模型的补充实验结果。这些结果如下表 11 所示。
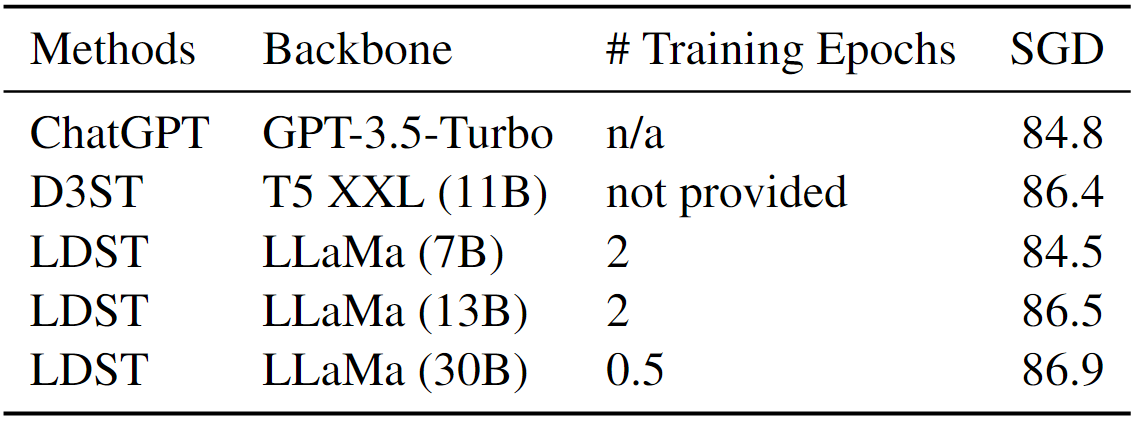
表 11:不同大小的模型的 JGA(%)
研究结果显示,随着模型规模的增大,JGA 分数也相应提升。然而,在实际应用中,7B 模型不仅更适合本地部署,而且性能出色。
B.4 推理时间分析
下表 12 展示了推理时间的结果。值得注意的是,我们对 LLM 采用了 8-bit 量化,与标准的 32-bit 相比推理时间较慢。
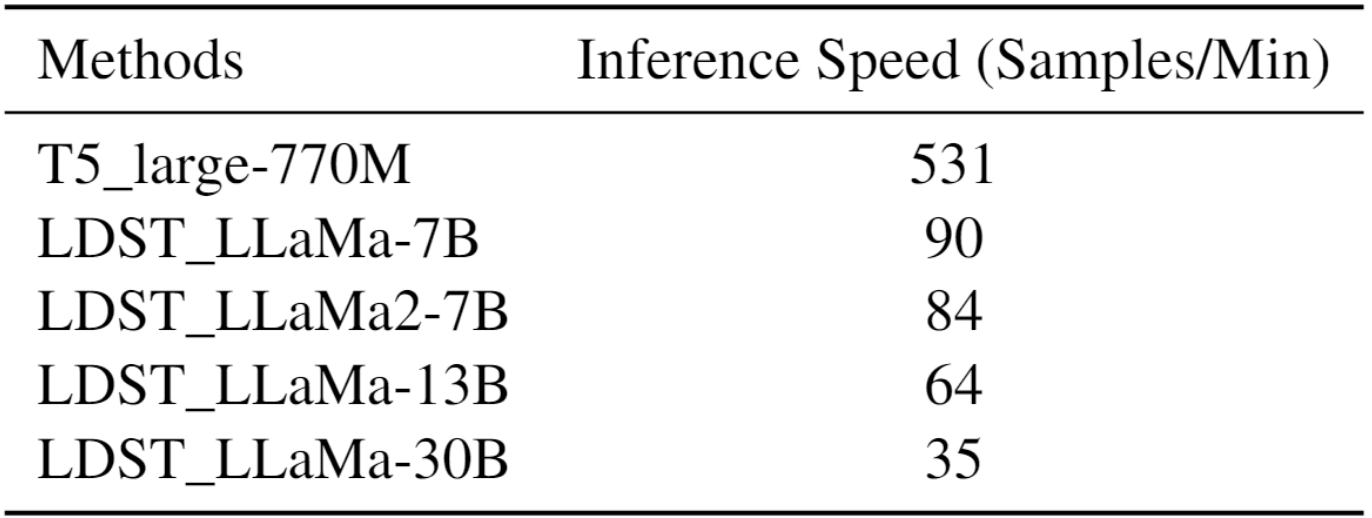
表 12:不同模型的推理时间
T5 large 是 SDP-DST 方法的骨干模型。从表中可见,随着模型规模的扩大,推理速度会有所减慢。具体来说,LDST_LLaMa-7B 平均每分钟可以预测 90 个样本。相较于基于 T5-large(770M)的 baseline 方法,LDST 的速度大约是其六倍。
B.5 LoRA 配置的效果
在我们的工作中,我们采用了常见的配置,即设置 lora_r = 8,并且 lora target = [query_proj, key_proj, value_proj, output_proj]。这一配置应用于每个需要更新的自注意力模块中。
为了进一步探讨 LoRA 配置对实验结果的影响,我们对 Multiwoz 2.4 数据集进行了额外分析。为了节省训练时间,我们将 epoch 设定为 1,并使用训练集的 1% 来进行这项研究。在这个实验中,我们改变了 lora_r 参数的值,分别尝试了 1、2、3、4、8 和 16。此外,我们还探索了两种不同的lora_target_modules 配置,分别是 [q_proj, v_proj] 和 [q_proj, k_proj, v_proj, o_proj]。这样,我们总共设置了 10 个不同的实验条件。

表 13:不同 LoRA 配置参数下的 JGA(%)
这些结果表明,较小的 "lora_r" 值意味着 LoRA 参数较少。而 lora target 模块则决定了哪些模块会接收 LoRA 更新矩阵。一般而言,更新更多的注意力矩阵往往能够带来更好的结果,并且随着 "lora_r" 值的增加,模型的性能也会相应提升。然而,需要注意的是,更高的 "lora_r" 值可能会增加模型的训练时间。因此,选择合适的超参数对于模型的性能至关重要。
B.6 MultiWOZ 2.1 数据集上的结果
在综合评估中,参见表 14,展示了 MultiWOZ 2.1 数据集的结果。该表比较了 Heck 等人提出的 ChatGPT 与 Zhao 等人提出的 D3ST 方法之间的性能。
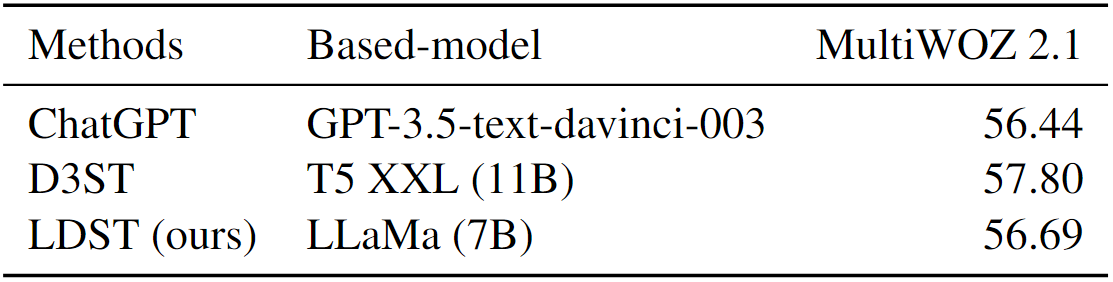
表 14:MultiWOZ 2.1 上的 JGA(%)
结果表明,LDST 的性能略低于 D3ST。这可能是由于测试集注释中存在的潜在噪声所致,这与我们对 MultiWOZ 2.2 数据集的观察结果相符。
C 实验细节
C.1 数据处理和评估
第一步 - 标准化处理
与 Lee 等人采用的方法相同,这一初始步骤涉及从原始数据中提取对话内容和 slot-value 对。以标签为 "PMUL4398.json" 的对话为例,该对话位于 Multiwoz 2.2 训练数据集中的 json 文件中。这段对话包含系统与用户之间的 6 个回合交流。考虑到 Multiwoz 2.2 具有 49 个不同的槽,这段对话将产生 \(6\times49=294\) 个训练数据样本。下面是一个具体的例子:
1 | |
在此示例中,"dialogue" 字段包含了对话的内容,如 \((A_1, U_1), (A_2, U2)\),以及跟踪的槽 <restaurant-area> 及其描述。而 "state" 字段则代表了相应槽的值。如果在对话中没有提及某个槽,那么 "state" 字段的值将被设定为 NONE。
第二步 - 指令数据生成
尽管第一步中的预处理能够为我们提供有价值的数据,但其格式并不完全符合指令调优的需求,因此导致了实验性能的不足。为了解决这个问题,我们引入了一个额外的预处理阶段,称之为“指令数据生成模块”,如图 4 所示。该模块的主要目标是构建更加合适的提示,以优化实验性能。
上述段落详细介绍了整个预处理过程,该过程完成后可用于模型的训练和测试。
评估
在评估方面,我们采用了 Lee 等人提供的代码来计算 JGA 和 AGA 分数。如果一个预测与基本事实完全相符,那么它就被视为正确的。在测试阶段,我们运用了一个统一的 prompt 模板,该模板包含了域槽描述和潜在值列表。实验结果显示,由于这个模板能够提供更全面的槽信息,因此其表现略优于其他模板。
C.2 实验设置
在训练阶段,我们选择了 128 作为 batch size,并将学习率设定为 1e-4。至于 epoch 则根据具体的实验设置而有所不同。对于零样本实验,我们进行了 3 个 epoch 的训练。对于小样本实验,我们针对不同百分比的标记数据进行了实验:在 1% 的小样本实验中我们训练了 10 个 epoch,在 5% 的小样本实验中我们训练了 3 个 epoch;而在 10% 的小样本实验中,我们训练了 2 个 epoch。为了对完整数据集实验进行微调,我们选择了 2 个 epoch 进行训练。
该模型的截断长度设定为 512,这是基于数据分析得出的最佳值,因为它覆盖了 90% 以上的数据。对于输入长度超过 512 个标记的样本,我们将对其进行截断以适应该截止长度。此外,参数 "train_on_inputs" 被设置为 false,意味着模型仅根据最终输出来计算损失。
关于 LoRA 模块的超参数设定,我们将 lora rank 设为 8,alpha 值设为 16,并将 dropout rate 设定为 0.05。同时,我们选择了 "q_proj"、"k_proj"、"v_proj" 和 "o_proj" 作为 lora target 模块。为了降低模型的内存使用,我们进一步采用了 8-bit 量化技术来优化微调过程。
我们希望能为模型的训练时间比较提供更深入的见解。在我们对完整数据集进行微调的实验中,我们的模型平均训练时间为 8 小时。相比之下,强大的 baseline 方法,如 SDP-DST 和 DiCoS-DST ,在微调 T5 模型时,基于我们的测试,需要大约60小时。这种训练时间的显著差异凸显了我们方法的有效性。对于同时采用 PEFT 技术的 TOATOD 方法,其微调过程主要关注软提示,从而将整个运行时间缩短至 12 小时。这种运行时间与我们的方法相当,进一步证明了我们方法与传统方法相比的有效性。
在少样本实验的情况下,对于 1% 标记数据的训练时间为 5 小时,5% 标记数据的训练时间为 8 小时,而 10% 标记数据的训练时间约为 10 小时。相比之下,零样本实验的平均运行时间约为 12 小时。值得注意的是,在这些实验设置中,虽然我们的方法与传统方法相比没有显著缩短运行时间,但它确实在保持效率的同时实现了最实质性的性能改进。通过了解模型在各种实验设置下的运行时,我们得以全面了解训练模型所需的时间以及与其他 baseline 方法的比较,从而为我们提供了更深入的理解。